

JavaScript 语言自身只有字符串数据类型,没有二进制数据类型,但在处理像 TCP 流或文件流时,必须使用到二进制数据,因此在 Node.js 中,定义了一个 Buffer 类,该类用来创建一个专门存放二进制数据的缓存区,但是在深入展开之前,我们先来了解一下 JavaScript 当中的 ArrayBuffer,来看看它与 Node.js 当中的 Buffer 到底有什么区别?
本文部分内容截取自 Node.js 中的缓冲区(Buffer)究竟是什么?
ArrayBuffer
JavaScript 当中的 ArrayBuffer 对象用来表示『通用的、固定长度的』原始二进制数据缓冲区,代表储存二进制数据的一段内存,它不能直接操作,而是要通过 类型数组对象 或 DataView 对象来操作,它们会将缓冲区中的数据表示为特定的格式,并通过这些格式来读写缓冲区的内容
下面的例子创建了一个 8 字节的缓冲区,并使用一个 Int32Array 来引用它
1 | var buffer = new ArrayBuffer(8) |
TypedArray 视图
ArrayBuffer 对象作为内存区域,可以存放多种类型的数据(其本身只是一个 0 和 1 存放在一行里面的一个集合),同一段内存,不同数据有不同的解读方式,这就叫做视图(view),ArrayBuffer 有两种视图,一种是 TypedArray 视图,另一种是 DataView 视图,前者的数组成员都是同一个数据类型,后者的数组成员可以是不同的数据类型,同一个 ArrayBuffer 对象之上,可以根据不同的数据类型建立多个视图
1 | // 创建一个 8 字节的 ArrayBuffer |
视图的构造函数可以接受三个参数
- 第一个参数(必需),视图对应的底层
ArrayBuffer对象 - 第二个参数(可选),视图开始的字节序号,默认从
0开始 - 第三个参数(可选),视图包含的数据个数,默认直到本段内存区域结束
但是有一个需要注意的地方,byteOffset 必须与所要建立的数据类型一致,否则会报错
1 | const buffer = new ArrayBuffer(8) |
上面代码中,新生成一个 8 个字节的 ArrayBuffer 对象,然后在这个对象的第一个字节,建立带符号的 16 位整数视图,结果报错,这是因为带符号的 16 位整数需要两个字节,所以 byteOffset 参数必须能够被 2 整除,关于 ArrayBuffer 的内容就简单的介绍到这里,如果想了解更多可以参考 DataView
在 Node.js 当中的之所以设置 Buffer 这种方式,简单来说就是扮演了一个原生内存的角色,它模拟了像 C 语言才有的那种直接访问内存的方式,你可能想知道为什么我们不让程序直接访问内存,而是添加了这种抽象层,『因为直接访问内存将导致一些安全漏洞』
在简单的了解了一些 JavaScript 当中 ArrayBuffer 内容之后,我们下面就再来看看 Node.js 当中的 Buffer
Buffer
Node.js 里面的 Buffer,是一个二进制数据容器,类似于整数数组,但 Buffer 的大小是固定的、且在 V8 堆外分配物理内存,Buffer 的大小在被创建时确定,且无法调整,比如我们使用 fs 模块来读取文件内容的时候,返回的就是一个 Buffer
1 | fs.readFile('filename', function (err, buf) { |
Buffer 基本使用
在 Node.js 的 v6 之前的版本中,Buffer 实例是通过 Buffer 构造函数创建的,但是这种方式存在两个问题
- 参数复杂,内存分配,还是内存分配和内容写入,需要根据参数来确定
- 安全隐患,分配到的内存可能还存储着旧数据,这样就存在安全隐患
1 | // 本来只想申请一块内存,但是里面却存在旧数据 |
为了解决上述问题,使 Buffer 实例的创建更可靠、更不容易出错,各种 new Buffer() 构造函数已被废弃,并由 Buffer.from()、Buffer.alloc()、和 Buffer.allocUnsafe() 等方法替代,下面我们就来看看这三个方法有什么区别
Buffer.from()
返回一个新的 Buffer,其中包含给定内容的副本
1 | const b1 = Buffer.from('10') |
Buffer.alloc(size)
返回一个指定大小的新建的的『已初始化』的 Buffer,此方法比 Buffer.allocUnsafe(size) 慢,但能确保新创建的 Buffer 实例『永远不会包含可能敏感的旧数据』,如果 size 不是数字,则将会抛出 TypeError
1 | const bAlloc1 = Buffer.alloc(10) // 创建一个大小为 10 个字节的缓冲区 |
Buffer.allocUnsafe(size)
创建一个大小为 size 字节的新的『未初始化』的 Buffer,由于 Buffer 是未初始化的,因此分配的内存片段『可能包含敏感的旧数据』,在 Buffer 内容可读情况下,则可能会泄露它的旧数据,这个是不安全的,使用时要谨慎
1 | const bAllocUnsafe1 = Buffer.allocUnsafe(10) |
Buffer 与字符编码
Buffer 实例一般用于表示编码字符的序列,比如 UTF-8、 UCS2、 Base64 或十六进制编码的数据,通过使用显式的字符编码,就可以在 Buffer 实例与普通的 JavaScript 字符串之间进行相互转换
1 | const buf = Buffer.from('hello world', 'ascii') |
目前所支持的字符编码如下所示
ascii,仅支持7位ASCII数据,如果设置去掉高位的话,这种编码是非常快的utf8,多字节编码的Unicode字符,许多网页和其他文档格式都使用UTF-8utf16le,2或4个字节,小字节序编码的Unicode字符,支持代理对(U+10000至U+10FFFF)ucs2,utf16le的别名base64,Base64编码latin1,一种把Buffer编码成一字节编码的字符串的方式binary,latin1的别名,hex,将每个字节编码为两个十六进制字符
更多关于 ASCII,Unicode 和 UTF-8 相关内容可见 ASCII,Unicode 和 UTF-8
字符串与 Buffer 类型互转
下面我们来看看字符串与 Buffer 之间的类型互转,以及可能会遇到的乱码问题
字符串转 Buffer
如果不传递 encoding 默认按照 UTF-8 格式转换存储
1 | const buf = Buffer.from('Node.js 技术栈', 'UTF-8') |
Buffer 转换为字符串
Buffer 转换为字符串也很简单,使用 toString([encoding], [start], [end]) 方法,默认编码仍为 UTF-8,如果不传递 start、end 可实现全部转换,传了 start、end 可实现部分转换(这里要注意了)
1 | const buf = Buffer.from('Node.js 技术栈', 'UTF-8'); |
运行查看,可以看到以上输出结果为 Node.js � 出现了乱码,为什么?
为什么转换过程中会出现乱码
首先在上面示例中使用的默认编码方式 UTF-8,问题就出在这里,一个中文在 UTF-8 下占用三个字节,Node.js 技术栈中的这个技字在 buf 中对应的字节为 8a 80 e6,而我们的设定的范围为 0 ~ 9 因此只输出了 8a,这个时候就会造成字符被截断出现乱码,下面我们稍微调整一下示例的截取范围
1 | const buf = Buffer.from('Node.js 技术栈', 'UTF-8') |
可以看到已经正常输出了,所以说平常在使用过程当中如果遇到需要截取中文的情况下应当小心
Buffer 与 TypedArray
Buffer 实例也是 Uint8Array 实例,但是与 ECMAScript 2015 中的 TypedArray 规范还是有些微妙的不同,例如当 ArrayBuffer#slice() 创建一个切片的副本时,Buffer#slice() 的实现是在现有的 Buffer 上不经过拷贝直接进行创建,这也使得 Buffer#slice() 更高效,遵循以下注意事项,也可以从一个 Buffer 创建一个新的 TypedArray 实例
Buffer对象的内存是拷贝到TypedArray的,而不是共享的Buffer对象的内存是被解析为一个明确元素的数组,而不是一个目标类型的字节数组- 也就是说
new Uint32Array(Buffer.from([1, 2, 3, 4]))会创建一个包含[1, 2, 3, 4]四个元素的Uint32Array - 而不是一个只包含一个元素
[0x1020304]或[0x4030201]的Uint32Array
也可以通过TypeArray对象的.buffer属性创建一个新建的且与TypedArray实例共享同一分配内存的Buffer
- 也就是说
Buffer#slice() 和 Array#slice()
Array#slice()
Array 当中的 slice() 方法返回一个从开始到结束(不包括结束)选择的数组的一部分浅拷贝到一个新数组对象,且『原始数组不会被修改』
1 | var arr = ['AAA', 'BBB', 'CCC', 'DDD', 'EEE'] |
Buffer#slice()
Buffer 当中的 slice() 方法返回一个『指向相同原始内存』的新建的 Buffer,但做了偏移且通过 start 和 end 索引进行裁剪,需要注意的是,修改这个新建的 Buffer 切片,也会同时修改原始的 Buffer 的内存,因为这两个对象所分配的内存是重叠的
1 | const buf = Buffer.from('hello world') |
通过观察 Array#slice() 示例和 Buffer#slice() 示例的输出结果,我们更加直观地了解它们之间的差异,Buffer 对象的 slice() 方法具体实现如下
1 | Buffer.prototype.slice = function slice(start, end) { |
Buffer 内存机制
由于 Buffer 需要处理的是大量的二进制数据,假如用一点就向系统去申请,则会造成频繁的向系统申请内存调用,所以 Buffer 所占用的内存不再由 V8 分配,而是在 Node.js 的 C++ 层面完成申请,在 JavaScript 中进行内存分配,因此这部分内存我们称之为堆外内存

Buffer 模块的内部结构如下
1 | exports.Buffer = Buffer |
并且提供了四个接口
Buffer,二进制数据容器类,Node.js启动时默认加载SlowBuffer,同样也是二进制数据容器类,不过直接进行内存申请INSPECT_MAX_BYTES,限制bufObject.inspect()输出的长度kMaxLength,一次性内存分配的上限,大小为(2^31 - 1)
其中,由于 Buffer 经常使用,所以 Node.js 在启动的时候,就已经加载了 Buffer,而其他三个仍然需要使用对应的引用来进行使用(require('buffer').xxx),这里需要注意一点,就是关于 Buffer 的内存申请、填充、修改等涉及性能问题的操作,均通过 C++ 里面的 node_buffer.cc 来实现
内存分配的策略
Node.js 中 Buffer 内存分配太过常见,从系统性能考虑出发,Buffer 采用了如下的管理策略

Node.js 采用了 slab 机制进行预先申请、事后分配,是一种动态的管理机制,使用 Buffer.alloc(size) 传入一个指定的 size 就会申请一块固定大小的内存区域,slab 具有如下三种状态
full,完全分配状态partial,部分分配状态empty,没有被分配状态
8K 内存池
在 Node.js 应用程序启动时,为了方便地、高效地使用 Buffer,会创建一个大小为 8K 的内存池,所以是以 8KB 为界限来区分是小对象还是大对象
1 | Buffer.poolSize = 8 * 1024 // 8K |
在加载时直接调用了 createPool() 相当于直接初始化了一个 8KB 的内存空间,这样在第一次进行内存分配时也会变得更高效,另外在初始化的同时还初始化了一个新的变量 poolOffset = 0 这个变量会记录已经使用了多少字节,在 createPool() 函数中,通过调用 createUnsafeArrayBuffer() 函数来创建 poolSize(8KB)的 ArrayBuffer 对象,createUnsafeArrayBuffer() 函数的实现如下
1 | function createUnsafeArrayBuffer(size) { |
此时,新构造的 slab 如下所示

现在让我们来尝试分配一个大小为 2048 的 Buffer 对象,代码如下所示
1 | Buffer.alloc(2 * 1024) |
现在让我们先看下当前的 slab 内存是怎么样的?如下所示
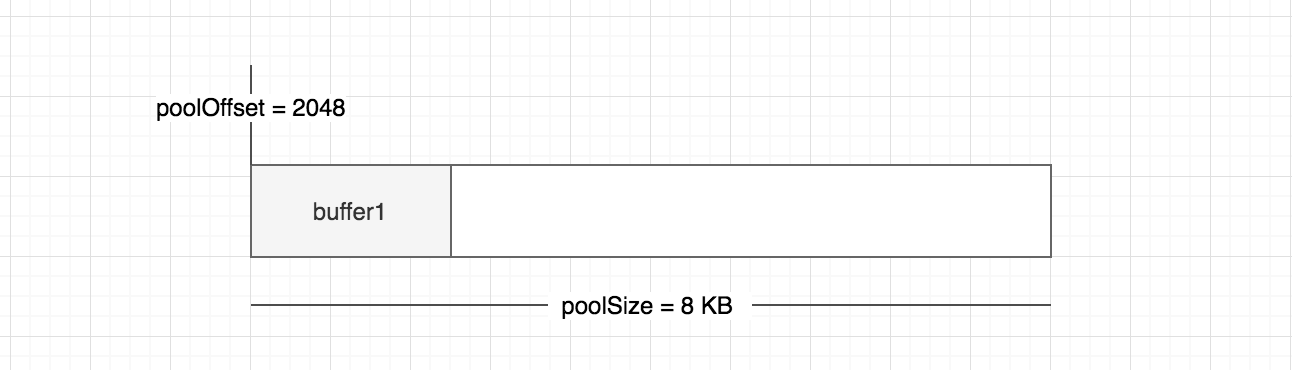
那么这个分配过程是怎样的呢?让我们再看 buffer.js 另外一个核心的方法 allocate(size)
1 | function allocate(size) { |
Buffer 内存分配总结
- 在初次加载时就会初始化
1个8KB的内存空间 - 根据申请的内存大小,
Buffer对象分为小对象和大对象 Buffer小对象的情况,会继续判断这个slab空间是否足够- 如果空间足够就去使用剩余空间同时更新
slab分配状态,偏移量会增加 - 如果空间不足,
slab空间不足,就会去创建一个新的slab空间用来分配
- 如果空间足够就去使用剩余空间同时更新
Buffer大对象情况,则会直接走createUnsafeBuffer(size)函数- 不论是小对象的还是大对象,内存分配是在
C++层面完成,内存管理在JavaScript层面,最终还是可以被V8的垃圾回收标记所回收
Buffer.from() 剖析
在我们使用 Buffer 的过程中,比如下面这个简单示例
1 | const buf = Buffer.from('hello world') |
运行以后可以发现,输出变成了
1 | <Buffer 68 65 6c 6c 6f 20 77 6f 72 6c 64> |
为什么结果会变成一串数字,这就要从源码找起了,如下
1 | /** |
可以看出 Buffer.from() 工厂函数,支持基于多种数据类型(string、Array、Buffer 等)创建 Buffer 对象,对于字符串类型的数据,内部调用 fromString(value, encodingOrOffset) 方法来创建 Buffer 对象
1 | class FastBuffer extends Uint8Array { |
简单的梳理如下,可以发现与上面的 Buffer 内存机制是相符的
- 当未设置编码的时候,默认使用
utf8编码 - 当字符串所需字节数大于
4KB,则直接进行内存分配 - 当字符串所需字节数小于
4KB,但超过预分配的8K内存池的剩余空间,则重新申请8K的内存池 - 调用
new FastBuffer(allocPool, poolOffset, length)创建FastBuffer对象,进行数据存储,数据成功保存后,会进行长度校验、更新poolOffset偏移量和字节对齐等操作
Buffer 应用场景
下面是一些 Buffer 在实际业务中的应用场景
I/O 操作
关于 I/O 可以是文件或网络 I/O,以下为通过流的方式将 input.txt 的信息读取出来之后写入到 output.txt 文件
1 | const fs = require('fs') |
在 Stream 中我们是不需要手动去创建自己的缓冲区,在 Node.js 的流中将会自动创建
zlib.js
zlib.js 为 Node.js 的核心库之一,其利用了缓冲区(Buffer)的功能来操作二进制数据流,提供了压缩或解压功能,见 zlib.js
加解密
在一些加解密算法中会遇到使用 Buffer,例如 crypto.createCipheriv 的第二个参数 key 为 string 或 Buffer 类型,使用 Buffer.alloc() 初始化一个实例,然后使用 fill 方法进行填充,语法为
1 | buf.fill(value[, offset[, end]][, encoding]) |
value,第一个参数为要填充的内容offset,偏移量,填充的起始位置end,结束填充buf的偏移量encoding,编码集
以下为使用 Cipher 对称加密的示例
1 | const crypto = require('crypto') |
缓冲(Buffer)与缓存(Cache)的区别
缓冲(Buffer)
缓冲(Buffer)是用于处理二进制流数据,将数据缓冲起来,它是临时性的,对于流式数据,会采用缓冲区将数据临时存储起来,等缓冲到一定的大小之后在存入硬盘中,视频播放器就是一个经典的例子,有时你会看到一个缓冲的图标,这意味着此时这一组缓冲区并未填满,当数据到达填满缓冲区并且被处理之后,此时缓冲图标消失,你可以看到一些图像数据
缓存(Cache)
缓存(Cache)我们可以看作是一个中间层,它可以是永久性的将热点数据进行缓存,使得访问速度更快,例如我们通过 Memory、Redis 等将数据从硬盘或其它第三方接口中请求过来进行缓存,目的就是将数据存于内存的缓存区中,这样对同一个资源进行访问,速度会更快,也是性能优化一个重要的点
更多区别可以参考 Cache 和 Buffer 都是缓存,主要区别是什么?
字节对齐
截取自 数据结构对齐 - 维基百科,所谓的字节对齐,就是各种类型的数据按照一定的规则在空间上排列,而不是顺序的一个接一个的排放,这个就是对齐,我们经常听说的对齐在 N 上,它的含义就是数据的存放起始地址 %N== 0,首先还是让我们来看一下,为什么要进行字节对齐吧
这是因为各个硬件平台对存储空间的处理上有很大的不同,一些平台对某些特定类型的数据只能从某些特定地址开始存取,比如有些架构的 CPU,诸如 SPARC 在访问一个没有进行对齐的变量的时候会发生错误,那么在这种架构上必须编程必须保证字节对齐,而有些平台对于没有进行对齐的数据进行存取时会产生效率的下降
让我们来以 x86 为例看一下如果在不进行对齐的情况下,会带来什么样子的效率低下问题,看下面的数据结构声明
1 | struct A { |
假设变量 a 存放在内存中的起始地址为 0x00,那么其成员变量 c 的起始地址为 0x00,成员变量 i 的起始地址为0x01,变量 a 一共占用了 5 个字节,当 CPU 要对成员变量 c 进行访问时,只需要一个读周期即可
然而如果要对成员变量 i 进行访问,那么情况就变得有点复杂了,首先 CPU 用了一个读周期,从 0x00 处读取了 4 个字节(注意由于是 32 位架构),然后将 0x01 - 0x03 的 3 个字节暂存,接着又花费了一个读周期读取了从 0x04 - 0x07 的 4 字节数据,将 0x04 这个字节与刚刚暂存的 3 个字节进行拼接从而读取到成员变量 i 的值
为了读取这个成员变量 i,CPU 花费了整整 2 个读周期,试想一下,如果数据成员 i 的起始地址被放在了 0x04 处,那么读取其所花费的周期就变成了 1,显然引入字节对齐可以避免读取效率的下降,但这同时也浪费了 3 个字节的空间(0x01 - 0x03)
了解完字节对齐的概念和使用字节对齐的原因,最后我们来看一下 Buffer.js 文件中的实现字节对齐的 alignPool() 函数
1 | /** |


