

为了让 Node.js 的文件可以相互调用,Node.js 提供了一个简单的模块系统,模块是 Node.js 应用程序的基本组成部分,文件和模块是一一对应的,换言之,一个 Node.js 文件就是一个模块,这个文件可能是 JavaScript 代码、JSON 或者编译过的 C/C++ 扩展
CommonJS 规范
Node.js 遵循 CommonJS 规范,该规范的核心思想是允许模块通过 require 方法来同步加载所要依赖的其他模块,然后通过 exports 或 module.exports 来导出需要暴露的接口,CommonJS 规范是为了解决 JavaScript 的作用域问题而定义的模块形式,可以使每个模块它自身的命名空间中执行,下面是一个简单的示例
1 | // a.js |
CommonJS 也有浏览器端的实现,其原理是现将所有模块都定义好并通过 id 索引,这样就可以方便的在浏览器环境中解析了,可以参考 require1k 和 tiny-browser-require 源码
经常与 CommonJS 规范一起出现的还有 AMD 规范和 CMD 规范,在这里就不详细展开,感兴趣的可以参考 JavaSript 模块规范 - AMD 规范与 CMD 规范介绍,总结的很棒
模块分类
在 Node.js 中,模块主要可以分为以下几种类型
- 核心模块,包含在
Node.js源码中,被编译进Node.js可执行二进制文件JavaScript模块,也叫Native模块,比如常用的HTTP,fs等等 C/C++模块,也叫built-in模块,一般我们不直接调用,而是在native module中调用,然后我们再requireNative模块,比如我们在Node.js中常用的Buffer,fs,os等Native模块,其底层都有调用built-in模块- 如对于
Native模块Buffer,还是需要借助builtin node_buffer.cc中提供的功能来实现大容量内存申请和管理,目的是能够脱离V8内存大小使用限制
- 如对于
- 第三方模块,非
Node.js源码自带的模块都可以统称第三方模块,比如express,Webpack等等JavaScript模块,这是最常见的,我们开发的时候一般都写的是JavaScript模块JSON模块,就是一个JSON文件C/C++扩展模块,使用C/C++编写,编译之后后缀名为.node
源码的目录结构如下
1 | ├── benchmark // 一些 Node.js 性能测试代码 |
模块对象
每个模块内部,都有一个 module 对象,代表当前模块,它有以下属性
module.id,模块的识别符,通常是带有绝对路径的模块文件名module.filename,模块的文件名,带有绝对路径module.loaded,返回一个布尔值,表示模块是否已经完成加载module.parent,返回一个对象,表示调用该模块的模块module.children,返回一个数组,表示该模块要用到的其他模块module.exports,表示模块对外输出的值
模块加载机制
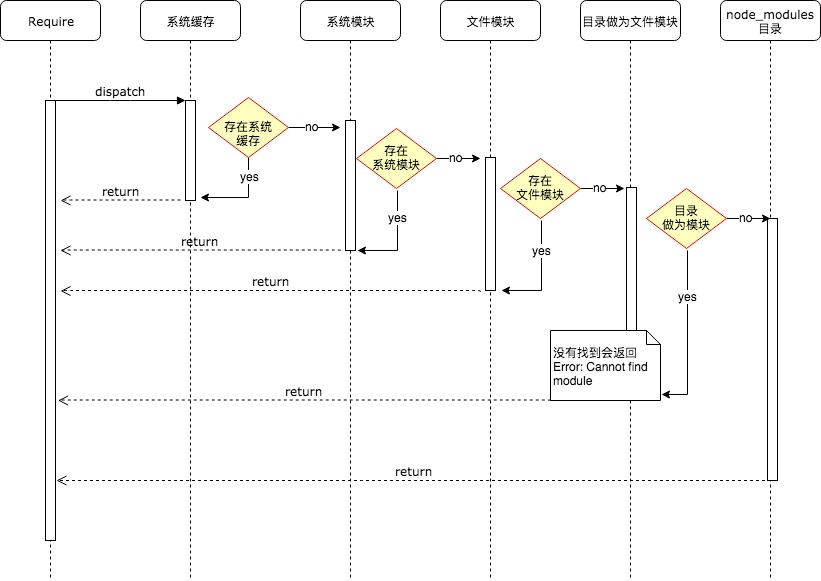
简单来说,模块加载机制也就是 require 函数执行的主要流程,在 Node.js 中模块加载一般会经历三个步骤,『路径分析』、『文件定位』、『编译执行』,按照模块的分类,按照以下顺序进行优先加载
- 系统缓存,模块被执行之后会会进行缓存,首先是先进行缓存加载,判断缓存中是否有值
- 系统模块,也就是原生模块,这个优先级仅次于缓存加载,部分核心模块已经被编译成二进制,省略了『路径分析』、『文件定位』,直接加载到了内存中,系统模块定义在
Node.js源码的lib目录下 - 文件模块,优先加载以
.、..、/开头的,如果文件没有加上扩展名,会依次按照.js、.json、.node进行扩展名补足尝试,那么在尝试的过程中也是以同步阻塞模式来判断文件是否存在- 从性能优化的角度来看待,
.json、.node最好还是加上文件的扩展名
- 从性能优化的角度来看待,
- 目录做为模块,这种情况发生在文件模块加载过程中,也没有找到,但是发现是一个目录的情况,这个时候会将这个目录当作一个『包』来处理
Node.js这块采用了Commonjs规范,先会在项目根目录查找package.json文件,取出文件中定义的main属性("main": "lib/hello.js")描述的入口文件进行加载- 如果也没加载到,则会抛出默认错误:
Error: Cannot find module 'lib/hello.js'
node_modules目录加载,对于系统模块、路径文件模块都找不到,Node.js会从当前模块的父目录进行查找,直到系统的根目录
我们在上面介绍了 Node.js 模块机制的一些基本内容,下面我们就来看一些 Node.js 模块当中可能涉及到的一些问题,主要有下面这些
- 模块中的
module、exports、__dirname、__filename和require来自何方? module.exports与exports有什么区别?- 模块之间循环依赖是否会陷入死循环?
require函数支持导入哪几类文件?require函数执行的主要流程是什么?Node.js模块与前端模块的异同Node.js中的VM模块是做什么用的?
模块中的 module、exports、dirname、filename 和 require 来自何方?
针对于这个问题,我们手动的试一下就知道了,新建一个 index.js 文件,输入以下内容
1 | console.log(module) |
执行完以上代码,控制台的输出如下,我们忽略掉输出对象中的大部分属性,只保留一些比较重要的,如下
1 | Module { ========================================================> module |
通过控制台的输出值,我们可以清楚地看出每个变量的值,在执行代码之前,Node.js 会对要执行的代码进行封装,至于到底是如何封装的,可以见下方 require 函数支持导入哪几类文件?,如下所示
1 | (function(exports, require, module, __filename, __dirname) { |
这里我们就清楚了,模块中的 module、exports、__dirname、__filename 和 require 这些对象都是函数的输入参数,在调用包装后的函数时传入
module.exports 与 exports 的区别
我们先来看一行代码
1 | console.log(module.exports === exports) // true |
可以发现,输出为 true,再看下面这样
1 | exports.id = 1 // 方式一,可以正常导出 |
为什么方式二无法正常导出呢?这里可以参考上面的 module 和 exports 输出的对应值来理解,如果 module.exports === exports 执行的结果为 true,那么表示模块中的 exports 变量与 module.exports 属性是指向同一个对象,当使用方式二 exports = { id: 1 } 的方式会改变 exports 变量的指向,这时与 module.exports 属性指向不同的变量,而当我们导入某个模块时,是导入 module.exports 属性指向的对象
如果想要深入了解,可以参考之前整理过的一篇文章内容 exports、module.exports 和 export、export default,分析的很详细
模块之间循环依赖是否会陷入死循环?
我们先来看看什么是循环依赖,所谓循环依赖就是,当模块 a 执行时需要依赖模块 b 中定义的属性或方法,而在导入模块 b 中,发现模块 b 同时也依赖模块 a 中的属性或方法,即两个模块之间互相依赖,这种现象我们称之为循环依赖,我们来验证一下
1 | // a.js |
当在控制台运行 a.js 之后可以发现程序正常运行,并不会出现死循环,但『只会输出相应模块已加载的部分数据』,如下
1 | { a: 1, b: 2 } |
所以我们可以得出结论,在启动 a.js 的时候,会加载 b.js,那么在 b.js 中又加载了 a.js,但是此时 a.js 模块还没有执行完,返回的是一个 a.js 模块的 exports 对象『未完成的副本』给到 b.js 模块(因此是不会陷入死循环的),然后 b.js 完成加载之后将 exports 对象提供给了 a.js 模块
require 函数支持导入哪几类文件?
在 require 函数对象中,有一个 extensions 属性,顾名思义表示它支持的扩展名,支持的文件类型主要有 .js、.json 和 .node,在上面输出的 require 函数对象中我们已经可以了解到了
1 | { |
我们再来深入一下,其实模块内的 require 函数对象是通过 lib/internal/module.js 文件中的 makeRequireFunction 函数创建的
1 | function makeRequireFunction(mod) { |
可以发现,在导入模块时,最终还是通过调用 Module 对象的 require() 方法来实现模块导入,在上面代码中,我们可以发现这一行 require.extensions = Module._extensions,在 lib/module.js 文件当中我们可以发现以下的定义
1 | // Native extension for .js |
这是 Node.js 针对处理的几种文件类型,这里我们主要看处理 .js 类型文件
1 | // Native extension for .js |
可以发现,首先我们会以同步的方式读取对应的文件内容,然后在使用 module._compile() 方法对文件的内容进行编译
1 | Module.prototype._compile = function (content, filename) { |
在这里,我们主要关注 var wrapper = Module.wrap(content) 这一行,调用 Module 内部的封装函数对模块的原始内容进行封装
1 | Module.wrap = function (script) { |
看到这里我们就可以明白,原来模块中的原始内容是在这个阶段进行包装的,包装后的格式为
1 | (function (exports, require, module, __filename, __dirname) { |
这也就解释了之前的模块中的 exports,require,module,__filename 和 __dirname 来自何方
require 函数执行的主要流程是什么?
在之前的章节中我们已经了解到了 require 函数执行的主要流程,其实就是模块加载机制,在加载对应模块前,我们首先需要定位文件的路径,文件的定位是通过 Module 内部的 _resolveFilename() 方法来实现,简化版的相关的伪代码描述如下
1 | 从 Y 路径的模块 require(X) |
下面就简单的看一下内部的 Module 对象的 require() 方法
1 | // Loads a module at the given file path. Returns that module's |
通过源码可以发现,其本质上是调用了 Module._load() 方法
1 | // Check the cache for the requested file. |
可以发现,与我们之前的模块加载机制是完全类似的,这里存在一个小问题,模块首次被加载后,会被缓存在 Module._cache 属性中,但有些时候,我们修改了已被缓存的模块,希望其它模块导入时,获取到更新后的内容的话该怎么处理呢?针对这种情况,我们可以使用以下方法清除指定缓存的模块,或清理所有已缓存的模块
1 | // 删除指定模块的缓存 |
Node.js 模块与前端模块的异同
通常有一些模块可以同时适用于前后端,但是在浏览器端通过 script 标签的载入 JavaScript 文件的方式与 Node.js 不同,Node.js 在载入到最终的执行中,进行了包装,使得每个文件中的变量天然的形成在一个闭包之中,不会污染全局变量,而浏览器端则通常是裸露的 JavaScript 代码片段,所以为了解决前后端一致性的问题,类库开发者需要将类库代码包装在一个闭包内,比如 underscore 的定义方式
1 | (function () { |
首先,它通过 function 定义构建了一个闭包,将 this 作为上下文对象直接 call 调用,以避免内部变量污染到全局作用域,续而通过判断 exports 是否存在来决定将局部变量 _ 绑定给 exports,并且根据 define 变量是否存在,作为处理在实现了 AMD 规范环境 下的使用案例
仅只当处于浏览器的环境中的时候,this 指向的是全局对象(window 对象),才将 _ 变量赋在全局对象上,作为一个全局对象的方法导出,以供外部调用,所以在设计前后端通用的 JavaScript 类库时,都有着以下类似的判断
1 | if (typeof exports !== 'undefined') { |
即,如果 exports 对象存在,则将局部变量挂载在 exports 对象上,如果不存在,则挂载在全局对象上
Node.js 中的 VM 模块是做什么用的?
VM 模块提供了一系列 API 用于在 V8 虚拟机环境中编译和运行代码,JavaScript 代码可以被编译并立即运行,或编译、保存然后再运行
vm.runInThisContext(code[, options])
vm.runInThisContext() 在当前的 global 对象的上下文中编译并执行 code,最后返回结果,运行中的代码无法获取本地作用域,但可以获取当前的 global 对象
1 | const vm = require('vm') |
正因 vm.runInThisContext() 无法获取本地作用域,故 localVar 的值不变,相反 eval() 确实能获取本地作用域,所以 localVar 的值被改变了


