

本章我们来看 Node.js 当中一个比较重要的概念,那就是 Stream,也就是所谓的流,那么什么是 Stream 呢?
什么是 Stream
Stream 的概念最早来源于 Unix 系统,其可以将一个大型系统拆分成一些小的组件,然后将这些小的组件可以很好地运行,TCP/IP 协议中的 TCP 协议也用到了 Stream 的思想,进而可以进行流量控制、差错控制,在 unix 中通过 | 来表示流,而在 Node.js 中则是通过 pipe() 方法,Stream 可以认为数据就像管道一样,多次不断地被传递下去,而不是一次性全部传递给下游
Node.js 中的流
在 Node.js API 文档 中可以看到下面一段话
1 | A stream is an abstract interface implemented by various objects in Node. |
简单来说
Stream是Node.js中一个非常重要的概念,被大量对象实现,尤其是Node.js中的I/O操作Stream是一个抽像的接口,一般不会直接使用,需要实现内部的某些抽象方法(例如_read、_write、_transform)Stream是EventEmitter的子类,实际上Stream的数据传递内部依然是通过事件(data)来实现的
流的分类
在 Node.js 中有四种类型的流,它们分别是 readable、writeable、Duplex 和 transform
readable,可读流,表示数据能够被消费,例如可以通过fs.createReadStream()方法创建可读流writeable,可写流,表示数据能被写,例如可以通过fs.createWriteStream()方法创建可写流duplex,即表示既是Readable流也是Writable流,如TCP Sockettransform,它也是Duplex流,能够用来修改或转换数据,例如zlib.createGzip方法用来使用gzip压缩数据(你可以认为transform流是一个函数,它的输入是Writable流,输出是Readable流)
| 使用情景 | 类 | 需要重写的方法 |
|---|---|---|
| 只读 | Readable |
_read |
| 只写 | Writable |
_write |
| 双工 | Duplex |
_read,_write |
| 操作被写入数据,然后读出结果 | Transform |
_transform,_flush |
此外所有的流都是 EventEmitter 的实例,它们能够监听或触发事件,用于控制读取和写入数据,Readable 与 Writable 流支持的常见的事件和方法如下图所示

下面我们就一个一个来分类介绍
Readable
可读流(Readable Streams)是对提供数据的源头(source)的抽象,可读流事实上工作在下面两种模式之一 flowing 和 paused
- 在
flowing模式下,可读流自动从系统底层读取数据,并通过EventEmitter接口的事件尽快将数据提供给应用 - 在
paused模式下,必须显式调用stream.read()方法来从流中读取数据片段
那如何触发这两种模式呢
paused mode,调用pause方法(没有pipe方法)、移除data事件和释放所有pipeflowing mode,注册事件data、调用resume方法、调用pipe方法
如下所示
1 | // data 事件触发 flowing mode |
简单来说,两种模式取决于一个 flowing 字段
1 | true ==> flowing mode |
上面三种方式最后均是通过 resume 方法,将 state.flowing = true,可读流的两种操作模式是一种简单抽象,它抽象了在可读流实现(Readable stream implementation)内部发生的复杂的状态管理过程,在任意时刻,任意可读流应确切处于下面三种状态之一
1 | readable._readableState.flowing = null |
若 readable._readableState.flowing 为 null,由于不存在数据消费者,可读流将不会产生数据,如果监听 data 事件,调用 readable.pipe() 方法,或者调用 readable.resume() 方法,readable._readableState.flowing 的值将会变为 true,这时,随着数据生成,可读流开始频繁触发事件
调用 readable.pause() 方法,readable.unpipe() 方法,或者接收背压(关于背压的概念我们会在下面进行介绍),将导致 readable._readableState.flowing 值变为 false,这将暂停事件流,但不会暂停数据生成,当 readable._readableState.flowing 值为 false 时, 数据可能堆积到流的内部缓存中
需要注意的是,应该选择其中『一种』来消费数据,而『不应该』在单个流使用多种方法来消费数据,对于大多数用户,建议使用 readable.pipe() 方法来消费流数据,因为它是最简单的一种实现,如果要精细地控制数据传递和产生的过程,可以使用 EventEmitter 和 readable.pause()/readable.resume() 提供的 API
paused mode
在 paused mode 下,需要手动地读取数据,并且可以直接指定读取数据的长度
1 | var Read = require('stream').Readable |
还可以通过监听事件 readable,触发时手工读取 chunk 数据
1 | var Read = require('stream').Readable |
需要注意的是,一旦注册了 readable 事件,必须手工读取 read 数据,否则数据就会流失,看看内部实现
1 | function emitReadable_(stream) { |
flow 方法直接 read 数据,将得到的数据通过事件 data 交付出去,然而此处没有注册 data 事件监控,因此,得到的 chunk 数据并没有交付给任何对象,这样数据就白白流失了,所以在触发 emit('readable') 时,需要提前 read 数据
flowing mode
通过注册 data、pipe、resume 可以自动获取所需要的数据,比如通过事件 data 的方式
1 | var Read = require('stream').Readable |
或者通过 pipe 的方式
1 | var Read = require('stream').Readable |
以上两种 mode 总体如下

readable 与 data 事件
read() 是 Readable 流的基石,无论流处于什么模式,只要是涉及读取数据最终都会转到 read() 上面来,它的主要功能是
- 读取缓冲区数据并返回给消费者,并按需发射各种事件
- 按需调用
_read(),_read()会从底层汲取数据,并填充缓冲区
它的流程大致如下

务必记住 read() 是『同步』的,因此它并不是直接从底层数据那里读取数据,而是从缓冲区读取数据,而缓冲区的数据则是由 _read() 负责补充
_read() 可以是同步或者异步,Node.js 内部的实现经常会调用 read(0),因为参数是 0 所以不会破坏缓冲区中的数据和状态,但可以触发 _read() 来从底层汲取数据并填充缓冲区,_read() 是流实现者需要重写的函数,它从底层汲取数据并填充缓冲区(flowing 模式不会填充而是直接发送给消费者),它的大致流程如下

注意在 addChunk() 后会根据情况发射 readable 或者 data 事件,然后依次调用
1 | read() ==> _read(0) ==> ... ==> addChunk() |
从而形成一个循环,因为一旦调用了 _read() 之后,流就会默默在底层读取数据,直到数据都消耗完为止
readable 事件
文档上关于 readable 事件的描述如下
事实上,
readable事件表明流有了新的动态,要么是有了新的数据,要么是到了流的尾部,对于前者stream.read()将返回可用的数据,而对于后者stream.read()将返回null
由此我们可以知道 readable 事件意味着
- 流有了新的数据(注意,这里只说明有了新数据,至于新数据如何读取是调用者自己的事情)
- 流到达了尾部
来看下面这个示例
1 | // 可以将 size 设为 1 或 undefined 来进行测试 |
总之,readable 只是负责通知用户流有了新的动态,事件发生的时候是否读取数据,如何读取数据则是调用者的事情(如果一直不读取事件,则数据会存在于缓冲区中),例如可以给 readable 注册一个回调函数,该回调函数调用无参的 read(),它会读取并清空缓冲区的全部数据,这样就使得每次 readable 发生的时候都可以读取到最新的数据
readable 的触发时机
readable 在以下几种情况会被触发
- 在
onEofChunk中,且_read()从底层汲取的数据为空,这个场景意味着流中的数据已经全部消耗完 - 在
addChunk()中,且_read()从底层汲取的数据不为空且处于pause模式,这个场景意味着流中有新数据 - 在
read(n)中,且n为0是的某些情况下 - 通过
on()为readable添加监听器,如果此时缓冲区有数据则会触发,这个场景意味着流中已经有数据可供read()直接调用
data 事件
data 事件的意义则明确很多,文档上关于 data 事件的描述如下
The ‘data’ event is emitted whenever the stream is relinquishing ownership of a chunk of data to a consumer.
与 readable 不同的是,data 事件代表的意义清晰单一,流将数据交付给消费者时触发,并且会将对应的数据通过回调传递给用户
data 的触发时机
从源码来看,有两个地方会触发 data 事件
- 在
read()中,如果缓冲区此时有数据可以返回给调用者,这种情况只会在调用pipe()时候发生,如果readable()被暂停过并重新启动,此时缓冲区内残留的数据会通过read()读出然后借助data事件传递出去 - 在
addChunk()中,此时_read()从底层汲取的数据不为空,且满足以下条件- 处于
flowing模式 - 缓冲区为空
- 处于异步调用模式
- 处于
在这种情况下,数据直接就交付给消费者了,并没有在缓冲区缓存,而文档中的说法是
当流转换到
flowing模式时会触发该事件,调用readable.pipe(),readable.resume()方法,或为data事件添加回调可以将流转换到flowing模式,data事件也会在调用readable.read()方法并有数据返回时触发
似乎两者不太一致?其实本质上调用 readable.pipe()、readable.resume() 或为 data 事件添加回调,最终都会依次调用
1 | read() ==> _read() ==> addChunk() |
然后最终才进行发射 data 事件,结合 _read() 的流程图,可以发现,通过 on() 为 readable 和 data 事件添加监听器后,程序就开始循环汲取底层数据直至消耗完为止
如果同时监听 readable 和 data 事件
如下示例
1 | const rs = require('fs').createReadStream('./test.js') |
运行结果如下
1 | <Buffer 63 6f 6e 73 74 20 72 73 20 3d 20 72 65 71 75 69 72 65 28 27 66 73 27 29 2e 63 72 65 61 74 65 52 65 61 64 53 74 72 65 61 6d 28 27 2e 2f 74 65 73 74 2e ... > |
从上面的流程图我们知道,在 addChunk() 中当有新数据到来的时候,redable 和 data 都有可能触发,那究竟触发哪个?让我们来看看 addChunk() 的源码
1 | function addChunk(stream, state, chunk, addToFront) { |
由于为 data 事件添加回调会使得流进入 flowing 模式,因此我们的例子中,有新数据时只会发射 data 事件,而 readable 事件则流结束的时候发射一次
Writable
所有 Writable 流都实现了 stream.Writable 类定义的接口,尽管特定的 Writable 流的实现可能略有差别,所有的 Writable streams 都可以按一种基本模式进行使用,如下
1 | const myStream = getWritableStreamSomehow() |
本质上 只是需要实现的是 _write(data, enc, next) 方法
1 | const Writable = require('stream').Writable |
上游通过调用 writable.write(data) 将数据写入可写流中,write() 方法会调用 _write() 将 data 写入底层,在 _write 方法中,当数据成功写入底层后,必须调用 next([err]) 告诉流开始处理下一个数据
next 的调用既可以是同步的,也可以是异步的,上游必须调用 writable.end(data) 来结束可写流,data 是可选的,此后,不能再调用 write 新增数据,在 end 方法调用后,当所有底层的写操作均完成时,会触发 finish 事件
Readable Stream 与 Writeable Stream
二者的关系
Readable Stream是提供数据的Stream,外部来源的数据均会存储到内部的Buffer数组内缓存起来writeable Stream是消费数据的Stream,从readable stream中获取数据,然后对得到的chunk块数据进行处理,至于如何处理,就依赖于具体实现(也就是_write的实现)
首先看看 Readdable Stream 与 writeable stream 二者之间的流动关系
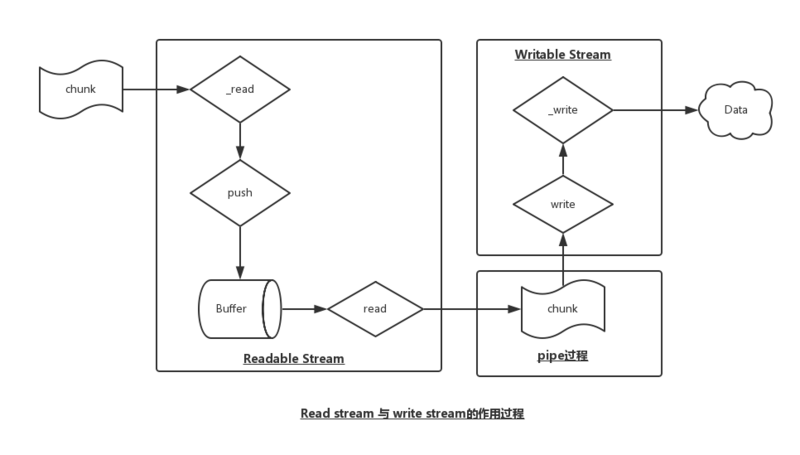
pipe 的流程
stream 内部是从 readable stream 流到 writeable stream,有两种处理方法
pipe 连接两个 stream
1 | var Read = require('stream').Readable |
pipe 是一种最简单直接的方法连接两个 stream,内部实现了数据传递的整个过程,在开发的时候不需要关注内部数据的流动
1 | Readable.prototype.pipe = function (dest, pipeOpts) { |
附一张 pipe() 的流程图

事件 data + 事件 drain 联合实现
1 | var Read = require('stream').Readable |
Duplex
Duplex 实际上就是继承了 Readable 和 Writable 的一类流,所以,一个 Duplex 对象既可当成可读流来使用(需要实现 _read 方法),也可当成可写流来使用(需要实现 _write 方法)
1 | var Duplex = require('stream').Duplex |
上面的代码中实现了 _read 方法,所以可以监听 data 事件来消耗 Duplex 产生的数据,同时,又实现了 _write 方法,可作为下游去消耗数据,因为它既可读又可写,所以它有两端,可写端和可读端,可写端的接口与 Writable 一致,作为下游来使用,可读端的接口与 Readable 一致,作为上游来使用,下面是另外一个示例,读取从 A 到 Z 的字母
1 | const { Duplex } = require('stream') |
我们将可读的 stdin 流传输到 duplex stream 当中以使用 callback(),然后将 duplex stream 本身传输到可写的 stdout 流以查看我们的输出结果
Transform
Tranform 继承自 Duplex,并已经实现了 _read 和 _write 方法,我们只需要实现将两者结合起来的 transform 方法即可,它具有 write 方法,我们可以使用它来推送数据

下面是一个简单的 transform stream 示例,它会将你的输入结果转换为大写
1 | const { Transform } = require('stream') |
内置的 transform stream
Node.js 有一些内置的 transform stream,比如 zlib 和 crypto,下面是一个使用 zlib.createGzip() 方法结合 fs 的 readable/writable 流实现的一个文件压缩示例
1 | const fs = require('fs') |
上述示例可以将传递进来的文件进行 gzip 压缩,下面我们来稍微扩展一下,比如我们希望用户在运行时可以看到进度结果,并且在完成的时侯看到已经完成的提示
1 | const fs = require('fs') |
在上面示例当中,我们也可以不使用 on 去监听其中的数据事件,而只需创建一个 transform stream 来追踪进度,然后将 .on() 方法替换为另一个 .pipe() 即可
1 | const fs = require('fs') |
注意上面示例当中的 callback() 方法的第二个参数,这样写是为了优先推送数据,在或者,我们需要在 gzip 压缩之前或之后对文件进行加密,和上面的示例一样,我们只需要按照我们想要的顺序添加另外一个 transform stream 即可
1 | const crypto = require('crypto') |
当然,为了解压上面我们压缩过的内容,我们只需要以相反的顺序执行 crypto 和 zlib 即可
1 | fs.createReadStream(file) |
自定义流
自定义流的实现很简单,只要实现相应的内部待实现方法就可以了,具体来说
readable stream,实现_read方法来解决数据的获取问题writeable stream,实现_write方法来解决数据的去向问题tranform stream,实现_tranform方法来解决数据存放在Buffer前的转换工作
代码如下
1 | // 自定义 readable stream 的实现 |
背压
我们在上面介绍可读流(Readable Streams)的时候,提及了一个背压的概念,下面我们就来看看到底什么是背压,本小结内容主要是参考 Backpressuring in Streams 这个文章整合而成
数据流中的积压问题
通常在数据处理的时候我们会遇到一个普遍的问题,那就是背压,意思是在数据传输过程中有一大堆数据在缓存之后积压着,每次当数据到达结尾又遇到复杂的运算,又或者无论什么原因它比预期的慢,这样累积下来,从源头来的数据就会变得很庞大,像一个塞子一样堵塞住
为解决这个问题,必须存在一种适当的代理机制,确保流从一个源流入另外一个的时候是平滑顺畅的,不同的社区组织针对他们各自的问题单独做了解决,好例子比如 Unix 的管道和 TCP 的 Socket,在 Node.js 中,流(stream)已经是被采纳的解决方案
数据太多,速度太快
有太多的例子证明有时 Readable 传输给 Writable 的速度远大于它接受和处理的速度,如果发生了这种情况,消费者开始为后面的消费而将数据列队形式积压起来,写入队列的时间越来越长,也正因为如此,更多的数据不得不保存在内存中知道整个流程全部处理完毕,写入磁盘的速度远比从磁盘读取数据慢得多,因此当我们试图压缩一个文件并写入磁盘时,积压的问题也就出现了,因为写磁盘的速度不能跟上读磁盘的速度
1 | // 数据将会在读入侧堆积,这样写入侧才能和数据流的读入速度保持同步 |
这就是为什么说积压机制很重要,如果积压机制不存在,进程将用完你全部的系统内存,从而对其它进程产生显著影响,它独占系统大量资源直到任务完成为止,这最终将会导致一些问题
- 明显使得其它进程处理变慢
- 太多繁重的垃圾回收
- 内存耗尽
pipe 的背压平衡机制
假设现在有一对 Readable 和 Writable,要求编程实现从 Readable 里面读取数据然后写到 Writable 中,那么面临的问题很有可能就是如果两者对数据的产生/消费速度不一致,那么需要手动协调两者速度使得任务可以完成,思路可能这样
Readable进入flowing模式,然后进入步骤2- 听
data事件,一旦有数据到达则进入步骤2,如果捕捉到end事件就结束任务 - 数据写入到
Writable,如果返回true进入步骤1,否则进入步骤3 Readable进入pause模式,并等待Writable发射drain事件- 果
Writable发射了drain事件,则返回步骤1
而事实上 pipe() 的过程和上述很相似,它的源码如下
1 | Readable.prototype.pipe = function (dest, pipeOpts) { |
通过上面的代码我们可以看到
- 当向
dest写入数据返回false时,马上调用src.pause()暂停流,src.pause()将暂停事件流,但不会暂停数据生成 - 也就是说
src此时依然汲取底层数据填充缓冲区,只是暂停发射data事件,等到缓冲区的数据量超过警戒线才会停止汲取 - 因为写入数据返回
false,因此在稍后的某个时候dest必然会发射drain事件 - 当
drain事件发生后,src再次进入flowing模式自动产生数据,同时将缓冲区中的残留数据写入dest
.pipe() 的生命周期
为了对积压有一个更好的理解,这里有一副 Readable 流正通过 piped 流入 Writable 流的整个生命周期图
1 | +===================+ |
注意,如果你创建一些管道准备把一些流串联起来从而操纵数据,你应该实现 Transform 流,在这种情况下,从 Readable 流中的输出进入 Transform,并且会被管道输送进入 Writable
1 | Readable.pipe(Transformable).pipe(Writable) |
积压将被自动应用,但是同时请注意输入和输出 Transform 的水准值,可以手动控制,并且会影响到积压系统,如果想要了解更多,可以参考 通过源码解析 Node.js 中导流(pipe)的实现 这篇文章
总结
在 Node.js 中有四种类型的流,它们是 readable、writeable、duplex 和 transform
readable,可读流,表示数据能够被消费,是对提供数据的源头(source)的抽象,工作在下面两种模式之一- 在
flowing模式下,可读流自动从系统底层读取数据,并通过EventEmitter接口的事件尽快将数据提供给应用- 通过注册
data、pipe、resume可以自动获取所需要的数据,比如通过事件data的方式
- 通过注册
- 在
paused模式下,必须显式调用stream.read()方法来从流中读取数据片段- 在
paused mode下,需要手动地读取数据,并且可以直接指定读取数据的长度 - 还可以通过监听事件
readable,触发时手工读取chunk数据 - 一旦注册了
readable事件,必须手工读取read数据,否则数据就会流失
- 在
- 如何触发
paused mode,调用pause方法(没有pipe方法)、移除data事件和释放所有pipeflowing mode,注册事件data、调用resume方法、调用pipe方法
- 在
writeable,可写流,表示数据能被写,所有Writable流都实现了stream.Writable类定义的接口- 本质上 只是需要实现的是
_write(data, enc, next)方法 - 在
_write方法中,当数据成功写入底层后,必须调用next([err])告诉流开始处理下一个数据 next的调用既可以是同步的,也可以是异步的- 上游必须调用
writable.end(data)来结束可写流,data是可选的,此后,不能再调用write新增数据 - 在
end方法调用后,当所有底层的写操作均完成时,会触发finish事件
- 本质上 只是需要实现的是
duplex,实际上就是继承了Readable和Writable的一类流- 一个
duplex对象既可当成可读流来使用(需要实现_read方法),也可当成可写流来使用(需要实现_write方法)
- 一个
transform,它也是duplex流,能够用来修改或转换数据,例如zlib.createGzip方法用来使用gzip压缩数据(内置的transform stream)- 你可以认为
transform流是一个函数,它的输入是Writable流,输出是Readable流 Tranform继承自duplex,并已经实现了_read和_write方法- 只需要实现将两者结合起来的
transform方法即可,它具有write方法,我们可以使用它来推送数据
- 你可以认为
推荐一下这篇文章 Node Stream,干货很多



