

最近在复习相关内容,感觉对于操作系统方面的知识都是一片空白,所以打算简单的学习学习,顺便简单的汇总整理一下,其实也就是一些基本概念的介绍,主要方便时不时回来看看复习一下
第一部分,体系结构基础
主要包括以下内容
- 冯·诺依曼体系结构
- 原码,反码和补码
- 位(
Bit)、字节(Byte)、字(Word)
冯·诺依曼体系结构
如下图
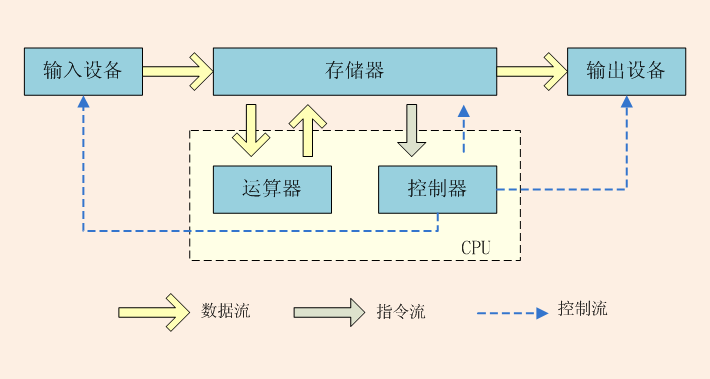
特点分为三部分
- 计算机处理的数据和指令一律用二进制数表示
- 顺序执行程序
- 计算机运行过程中,把要执行的程序和处理的数据首先存入主存储器(内存),计算机执行程序时,将自动地并按顺序从主存储器中取出指令一条一条地执行,这一概念称作顺序执行程序
- 计算机硬件由运算器、控制器、存储器、输入设备和输出设备五大部分组成
原码,反码和补码
在探求为何机器要使用补码之前,让我们先了解原码,反码和补码的概念,对于一个数,计算机要使用一定的编码方式进行存储,上面的三种方式是机器存储一个具体数字的编码方式
机器数
由于计算机中符号和数字一样,都必须用二进制数串来表示,因此正负号也必须用 0、1 来表示,用最高位 0 表示正、1 表示负,这种正负号数字化的机内表示形式就称为『机器数』,而相应的机器外部用正负号表示的数称为『真值』,将一个真值表示成二进制字串的机器数的过程就称为编码
原码
原码就是符号位加上真值的绝对值,即用第一位表示符号,其余位表示值,原码是人脑最容易理解和计算的表示方式,比如如果是 8 位二进制
1 | [+1]原 = 0000 0001 |
因为第一位是符号位,所以 8 位二进制数的取值范围就是
1 | [1111 1111 , 0111 1111] |
即
1 | [-127 , 127] |
反码
正数的反码是其本身,负数的反码是在其原码的基础上,符号位不变,其余各个位取反
1 | [+1] = [00000001]原 = [00000001]反 |
可见如果一个反码表示的是负数,人脑无法直观的看出来它的数值,通常要将其转换成原码再计算
补码
正数的补码就是其本身,负数的补码是在其原码的基础上,符号位不变,其余各位取反,最后 + 1(即在反码的基础上 + 1)
1 | [+1] = [00000001]原 = [00000001]反 = [00000001]补 |
对于负数,补码表示方式也是人脑无法直观看出其数值的,通常也需要转换成原码在计算其数值
定点数与浮点数
- 定点数是小数点固定的数,在计算机中没有专门表示小数点的位,小数点的位置是约定默认的
- 一般固定在机器数的最低位之后,或是固定在符号位之后,前者称为定点纯整数,后者称为定点纯小数
- 定点数表示法简单直观,但是数值表示的范围太小,运算时容易产生溢出
- 浮点数是小数点的位置可以变动的数,为增大数值表示范围,防止溢出,采用浮点数表示法
- 浮点表示法类似于十进制中的科学计数法
在计算机中通常把浮点数分成『阶码』和『尾数』两部分来表示,其中阶码一般用补码定点整数表示,尾数一般用补码或原码定点小数表示,为保证不损失有效数字,对尾数进行规格化处理,也就是平时所说的科学记数法,即保证尾数的最高位为 1,实际数值通过阶码进行调整,阶符表示指数的符号位、阶码表示幂次、数符表示尾数的符号位、尾数表示规格化后的小数值
1 | N = 尾数 × 基数阶码(指数) |
位(Bit)、字节(Byte)、字(Word)
- 位,位(
Bit)是电子计算机中最小的数据单位,每一位的状态只能是0或1 - 字节,
8个二进制位构成1个字节(Byte),它是存储空间的基本计量单位,1个字节可以储存1个英文字母或者半个汉字,换句话说,1个汉字占据2个字节的存储空间 - 字,由若干个字节构成,字(
Word)的位数叫做字长,不同档次的机器有不同的字长,例如一台8位机,它的1个字就等于1个字节,字长为8位,如果是一台16位机,那么,它的1个字就由2个字节构成,字长为16位,字是计算机进行数据处理和运算的单位
字节序
字节顺序是指占内存多于一个字节类型的数据在内存中的存放顺序,通常有小端、大端两种字节顺序
- 小端字节序指低字节数据存放在内存低地址处,高字节数据存放在内存高地址处
- 大端字节序是高字节数据存放在低地址处,低字节数据存放在高地址处
基于 X86 平台的 PC 机是小端字节序的,而有的嵌入式平台则是大端字节序的,所有网络协议也都是采用 big endian 的方式来传输数据的,所以有时我们也会把 big endian 方式称之为『网络字节序』,比如数字 0x12345678 在两种不同字节序 CPU 中的存储顺序如下所示
1 | Big Endian |
从上面两图可以看出,采用 Big Endian 方式存储数据是符合我们人类的思维习惯的,联合体 union 的存放顺序是所有成员都从低地址开始存放,利用该特性,就能判断 CPU 对内存采用 Little-endian 还是 Big-endian 模式读写
1 | union test { |
字节对齐
现代计算机中内存空间都是按照 byte 划分的,从理论上讲似乎对任何类型的变量的访问可以从任何地址开始,但实际情况是在访问特定类型变量的时候经常在特定的内存地址访问,这就需要各种类型数据按照一定的规则在空间上排列,而不是顺序的一个接一个的排放,这就是对齐,那么问题来了,为什么要进行字节对齐呢,主要因为下面两点原因
- 某些平台只能在特定的地址处访问特定类型的数据
- 最根本的原因是效率问题,字节对齐能提存取数据的速度
比如有的平台每次都是从偶地址处读取数据,对于一个 int 型的变量,若从偶地址单元处存放,则只需一个读取周期即可读取该变量,但是若从奇地址单元处存放,则需要 2 个读取周期读取该变量
字节对齐的原则
- 数据成员对齐规则,结构(
struct或联合)的数据成员,第一个数据成员放在offset为0的地方,以后每个数据成员存储的起始位置要从该成员大小或者成员的子成员大小(只要该成员有子成员,比如说是数组,结构体等)的整数倍开始(比如int在32位机为4字节,则要从4的整数倍地址开始存储) - 结构体作为成员,如果一个结构里有某些结构体成员,则结构体成员要从其内部最大元素大小的整数倍地址开始存储(
struct a里存有struct b,b里有char,int,double等元素,那b应该从8的整数倍开始存储) - 收尾工作,结构体的总大小,也就是
sizeof的结果,必须是其内部最大成员的整数倍,不足的要补齐
第二部分,操作系统基础
操作系统的五大功能,分别为『作业管理』、『文件管理』、『存储管理』、『输入输出设备管理』、『进程及处理机管理』,主要介绍以下内容
- 中断
- 系统调用
中断
所谓的中断就是在计算机执行程序的过程中,由于出现了某些特殊事情,使得 CPU 暂停对程序的执行,转而去执行处理这一事件的程序,等这些特殊事情处理完之后再回去执行之前的程序,中断一般分为三类
- 由计算机硬件异常或故障引起的中断,称为内部异常中断
- 由程序中执行了引起中断的指令而造成的中断,称为软中断(这也是和我们将要说明的系统调用相关的中断)
- 由外部设备请求引起的中断,称为外部中断,简单来说,对中断的理解就是对一些特殊事情的处理
中断处理程序
当中断发生的时候,系统需要去对中断进行处理,对这些中断的处理是由操作系统内核中的特定函数进行的,这些处理中断的特定的函数就是我们所说的中断处理程序了
中断的优先级
中断的优先级说明的是当一个中断正在被处理的时候,处理器能接受的中断的级别,中断的优先级也表明了中断需要被处理的紧急程度,每个中断都有一个对应的优先级,当处理器在处理某一中断的时候,只有比这个中断优先级高的中断可以被处理器接受并且被处理,优先级比这个当前正在被处理的中断优先级要低的中断将会被忽略,典型的中断优先级如下所示
1 | 机器错误 > 时钟 > 磁盘 > 网络设备 > 终端 > 软件中断 |
当发生软件中断时,其他所有的中断都可能发生并被处理,但当发生磁盘中断时,就只有时钟中断和机器错误中断能被处理了
系统调用
进程的执行在系统上的两个级别是用户级和核心级,也称为用户态和系统态(user mode and kernel mode),程序的执行一般是在用户态下执行的,但当程序需要使用操作系统提供的服务时,比如说打开某一设备、创建文件、读写文件等,就需要向操作系统发出调用服务的请求,这就是系统调用
Linux 系统有专门的函数库来提供这些请求操作系统服务的入口,这个函数库中包含了操作系统所提供的对外服务的接口,当进程发出系统调用之后,它所处的运行状态就会由用户态变成核心态,但这个时候,进程本身其实并没有做什么事情,这个时候是由内核在做相应的操作,去完成进程所提出的这些请求
系统调用和中断的关系就在于,当进程发出系统调用申请的时候,会产生一个软件中断,产生这个软件中断以后,系统会去对这个软中断进行处理,这个时候进程就处于核心态了,那么用户态和核心态之间的区别是什么呢?(摘至《UNIX 操作系统设计》)
- 用户态的进程能存取它们自己的指令和数据,但不能存取内核指令和数据(或其他进程的指令和数据),然而核心态下的进程能够存取内核和用户地址
- 某些机器指令是特权指令,在用户态下执行特权指令会引起错误
对此要理解的一个是,在系统中内核并不是作为一个与用户进程平行的估计的进程的集合,内核是为用户进程运行的
第三部分,并发技术
主要介绍以下内容
- 进程
- 线程
- 锁
- 协程
IO多路复用
多任务
在上古时代,CPU 资源十分昂贵,如果让 CPU 只能运行一个程序,那么当 CPU 空闲下来(例如等待 I/O 时),CPU 就空闲下来了,为了让 CPU 得到更好的利用,人们编写了一个监控程序,如果发现某个程序暂时无须使用 CPU 时,监控程序就把另外的正在等待 CPU 资源的程序启动起来,以充分利用 CPU 资源,这种方法被称为『多道程序』(Multiprogramming)
对于多道程序来说,最大的问题是程序之间不区分轻重缓急,对于交互式程序来说,对于 CPU 计算时间的需求并不多,但是对于响应速度却有比较高的要求,而对于计算类程序来说则正好相反,对于响应速度要求低,但是需要长时间的 CPU 计算,想象一下我们同时在用浏览器上网和听音乐,我们希望浏览器能够快速响应,同时也希望音乐不停掉,这时候多道程序就没法达到我们的要求了,于是人们改进了多道程序,使得每个程序运行一段时间之后,都主动让出 CPU 资源,这样每个程序在一段时间内都有机会运行一小段时间,这样像浏览器这样的交互式程序就能够快速地被处理,同时计算类程序也不会受到很大影响,这种程序协作方式被称为『分时系统』(Time-Sharing System)
在分时系统的帮助下,我们可以边用浏览器边听歌了,但是如果某个程序出现了错误,导致了死循环,不仅仅是这个程序会出错,整个系统都会死机,为了避免这种情况,一个更为先进的操作系统模式被发明出来,也就是我们现在很熟悉的『多任务』(Multi-tasking)系统,操作系统从最底层接管了所有硬件资源,所有的应用程序在操作系统之上以『进程』(Process) 的方式运行,每个进程都有自己独立的地址空间,相互隔离,CPU 由操作系统统一进行分配,每个进程都有机会得到 CPU,同时在操作系统控制之下,如果一个进程运行超过了一定时间,就会被暂停掉,失去 CPU 资源,这样就避免了一个程序的错误导致整个系统死机,如果操作系统分配给各个进程的运行时间都很短,CPU 可以在多个进程间快速切换,就像很多进程都同时在运行的样子,几乎所有现代操作系统都是采用这样的方式支持多任务,例如 Unix,Linux,Windows 以及 macOS
进程
进程是一个具有独立功能的程序关于某个数据集合的一次运行活动,它可以申请和拥有系统资源,是一个动态的概念,是一个活动的实体,它不只是程序的代码,还包括当前的活动,通过程序计数器的值和处理寄存器的内容来表示
进程的概念主要有以下两点
- 进程是一个实体,每一个进程都有它自己的地址空间,一般情况下,包括文本区域(
text region)、数据区域(data region)和堆栈(stack region)- 文本区域存储处理器执行的代码
- 数据区域存储变量和进程执行期间使用的动态分配的内存
- 堆栈区域存储着活动过程调用的指令和本地变量
- 进程是一个执行中的程序
程序是一个没有生命的实体,只有处理器赋予程序生命时,它才能成为一个活动的实体,我们称其为进程
进程的基本状态
有三个状态
- 等待态,等待某个事件的完成
- 就绪态,等待系统分配处理器以便运行
- 运行态,占有处理器正在运行
1 | 运行态 ==> 等待态,往往是由于等待外设,等待主存等资源分配或等待人工干预而引起的 |
进程调度
调度种类分为高级、中级和低级,调度作业从提交开始直到完成,往往要经历下述三级调度
- 高级调度(
High-Level Scheduling),又称为作业调度,它决定把后备作业调入内存运行 - 中级调度(
Intermediate-Level Scheduling),又称为在虚拟存储器中引入,在内、外存对换区进行进程对换 - 低级调度(
Low-Level Scheduling),又称为进程调度,它决定把就绪队列的某进程获得CPU
非抢占式调度与抢占式调度
- 非抢占式
- 分派程序一旦把处理机分配给某进程后便让它一直运行下去,直到进程完成或发生进程调度进程调度某事件而阻塞时,才把处理机分配给另一个进程
- 抢占式
- 操作系统将正在运行的进程强行暂停,由调度程序将
CPU分配给其他就绪进程的调度方式
- 操作系统将正在运行的进程强行暂停,由调度程序将
调度策略的设计
- 响应时间,从用户输入到产生反应的时间
- 周转时间,从任务开始到任务结束的时间
CPU 任务可以分为『交互式任务』和『批处理任务』,调度最终的目标是合理的使用 CPU,使得交互式任务的响应时间尽可能短,用户不至于感到延迟,同时使得批处理任务的周转时间尽可能短,减少用户等待的时间
调度算法
- 先来先服务调度算法(
FCFS) - 短作业优先(
SJF)的调度算法 - 时间片轮转调度算法(
RR) - 优先级调度算法(
HPF) - 多级反馈队列调度算法
- 高响应比优先调度算法
关于调度算法详细内容可以参考 作业调度算法 这篇文章
临界资源与临界区
在操作系统中,进程是占有资源的最小单位(线程可以访问其所在进程内的所有资源,但线程本身并不占有资源或仅仅占有一点必须资源),但对于某些资源来说,其在同一时间只能被一个进程所占用,这些一次只能被一个进程所占用的资源就是所谓的临界资源,典型的临界资源比如物理上的打印机,或是存在硬盘或内存中被多个进程所共享的一些变量和数据等(如果这类资源不被看成临界资源加以保护,那么很有可能造成丢数据的问题)
对于临界资源的访问,必须是互斥进行,也就是当临界资源被占用时,另一个申请临界资源的进程会被阻塞,直到其所申请的临界资源被释放,而进程内访问临界资源的代码被称为『临界区』,对于临界区的访问过程分为四个部分
- 进入区,查看临界区是否可访问,如果可以访问,则转到步骤二,否则进程会被阻塞
- 临界区,在临界区做操作
- 退出区,清除临界区被占用的标志
- 剩余区,进程与临界区不相关部分的代码
解决临界区问题可能的方法
- 一般软件方法
- 关中断方法
- 硬件原子指令方法
- 信号量方法
信号量
信号量是一个确定的二元组(s, q),其中 s 是一个具有非负初值的整形变量,q 是一个初始状态为空的队列,整形变量 s 表示系统中某类资源的数目
- 当其值
>= 0时,表示系统中当前可用资源的数目 - 当其值
< 0时,其绝对值表示系统中因请求该类资源而被阻塞的进程数目
除信号量的初值外,信号量的值仅能由 P 操作和 V 操作更改,操作系统利用它的状态对进程和资源进行管理
P操作记为P(s),其中s为一信号量,它执行时主要完成s.value = s.value - 1(可理解为占用1个资源,若原来就没有则记帐欠1个)- 若
s.value >= 0,则进程继续执行,否则(即s.value < 0)则进程被阻塞,并将该进程插入到信号量s的等待队列s.queue中 - 实际上,
P操作可以理解为分配资源的计数器,或是使进程处于等待状态的控制指令
- 若
V操作记为V(s),其中s为一信号量,它执行时,主要完成s.value = s.value + 1(可理解为归还1个资源,若原来就没有则意义是用此资源还1个欠帐)- 若
s.value > 0,则进程继续执行,否则(即s.value <= 0)则从信号量s的等待队s.queue中移出第一个进程,使其变为就绪状态,然后返回原进程继续执行 - 实际上,
V操作可以理解为归还资源的计数器,或是唤醒进程使其处于就绪状态的控制指令
- 若
下面是一个信号量方法实现生产者和消费者之间的互斥与同步控制的示例
1 | semaphore fullBuffers = 0; /* 仓库中已填满的货架个数 */ |
死锁
死锁表示多个进程因循环等待资源而造成无法执行的现象,死锁会造成进程无法执行,同时会造成系统资源的极大浪费(资源无法释放),死锁产生的四个必要条件
- 互斥使用(
Mutual exclusion)- 指进程对所分配到的资源进行排它性使用,即在一段时间内某资源只由一个进程占用,如果此时还有其它进程请求资源,则请求者只能等待,直至占有资源的进程用毕释放
- 不可抢占(
No preemption)- 指进程已获得的资源,在未使用完之前,不能被剥夺,只能在使用完时由自己释放
- 请求和保持(
Hold and wait)- 指进程已经保持至少一个资源,但又提出了新的资源请求,而该资源已被其它进程占有,此时请求进程阻塞,但又对自己已获得的其它资源保持不放
- 循环等待(
Circular wait)指在发生死锁时,必然存在一个『进程 ==> 资源』的环形链- 即进程集合
{ P0, P1, P2 ... Pn }中的P0正在等待一个P1占用的资源,P1正在等待P2占用的资源 …Pn正在等待已被P0占用的资源
- 即进程集合
避免死锁的方式可以采用 银行家算法,原理是判断此次请求是否造成死锁若会造成死锁,则拒绝该请求
进程间通信
本地进程间通信的方式有很多,可以总结为下面四类
- 消息传递(管道、
FIFO、消息队列) - 同步(互斥量、条件变量、读写锁、文件和写记录锁、信号量)
- 共享内存(匿名的和具名的)
- 远程过程调用(
Solaris Door和Sun RPC)
线程
多进程解决了前面提到的多任务问题,然而很多时候不同的程序需要共享同样的资源(文件,信号量等)如果全都使用进程的话会导致切换的成本很高,造成 CPU 资源的浪费,于是就出现了线程的概念,线程是操作系统能够进行运算调度的最小单位,『线程是隶属于进程的,被包含于进程之中』
一个线程只能隶属于一个进程,但是一个进程是可以拥有多个线程的
同一块代码,可以根据系统 CPU 核心数启动多个进程,每个进程都有属于自己的独立运行空间,进程之间是不相互影响的,同一进程中的多条线程将共享该进程中的全部系统资源,如虚拟地址空间,文件描述符和信号处理等,但同一进程中的多个线程有各自的调用栈(call stack),自己的寄存器环境(register context),自己的线程本地存储(thread-local storage),之所以设置线程这个单位,是因为
- 在一个程序中,多个线程可以同步或者互斥并行完成工作,简化了编程模型
- 线程较进程来讲,更轻
- 线程虽然微观并行,但是在一个进程内部,一个线程阻塞后,会执行这个进程内部的其他线程,而不是整体阻塞,提高了
CPU的利用率
下面是一个使用 pthread 线程库实现的生产者与消费者模型
1 | #include <pthread.h> |
单线程
单线程就是一个进程只开一个线程,所谓的单线程和多线程,本质上指在『一个进程内』的单线程和多线程
- 单线程,单线程就是一个进程中只有一个线程,程序顺序执行,前面的执行完,才会执行后面的程序
- 多线程,多线程就是一个进程中只有多个线程,在进程内部进行线程间的切换,由于每个线程执行的时间片很短,所以在感觉上是并行的
多线程
多线程就是没有一个进程只开一个线程的限制,可以有效避免代码阻塞导致的后续请求无法处理,多线程的代价还在于创建新的线程和执行期上下文线程的切换开销,由于每创建一个线程就会占用一定的内存,当应用程序并发大了之后,内存将会很快耗尽,类似于上面单线程模型中例举的例子,需要一定的计算会造成当前线程阻塞的,还是推荐使用多线程来处理
线程同步
线程同步是指多线程通过特定的东西(如互斥量)来控制线程之间的执行顺序(同步),也可以说是在线程之间通过同步建立起执行顺序的关系,如果没有同步那线程之间是各自运行各自的
锁
这里讨论的主要是多线程编程中需要使用的锁,我们不会去钻名词和概念的牛角尖,而是直接从本质上试图解释一下锁这个很常用的多线程编程工具,锁要解决的是线程之间争取资源的问题,这个问题大概有下面几个角度
- 资源是否是独占(独占锁 && 共享锁)
- 抢占不到资源怎么办(互斥锁 && 自旋锁)
- 自己能不能重复抢(重入锁 && 不可重入锁)
- 竞争读的情况比较多,读可不可以不加锁(读写锁)
上面这几个角度不是互相独立的,在实际场景中往往要它们结合起来,才能构造出一个合适的锁
独占锁 && 共享锁
- 当一个共享资源只有一份的时候,通常我们使用独占锁,常见的即各个语言当中的
Mutex,当共享资源有多份时,可以使用前面提到的『信号量』(Semaphere)
互斥锁 && 自旋锁
- 对于互斥锁来说,如果一个线程已经锁定了一个互斥锁,第二个线程又试图去获得这个互斥锁,则第二个线程将被挂起(即休眠,不占用
CPU资源) - 在计算机系统中,频繁的挂起和切换线程,也是有成本的,自旋锁就是解决这个问题的
- 自旋锁,指当一个线程在获取锁的时候,如果锁已经被其它线程获取,那么该线程将循环等待,然后不断的判断锁是否能够被成功获取,直到获取到锁才会退出循环
- 容易看出,当资源等待的时间较长,用互斥锁让线程休眠,会消耗更少的资源,当资源等待的时间较短时,使用自旋锁将减少线程的切换,获得更高的性能,简单说,它们在发现资源被抢占之后,会先试着自旋等待一段时间,如果等待时间太长,则会进入挂起状态,通过这样的实现,可以较大程度上挖掘出锁的性能
重入锁 && 不可重入锁
- 可重入锁(
ReetrantLock),也叫做递归锁,指的是在同一线程内,外层函数获得锁之后,内层递归函数仍然可以获取到该锁,换一种说法,即同一个线程再次进入同步代码时,可以使用自己已获取到的锁 - 使用可重入锁时,在同一线程中多次获取锁,不会导致死锁,使用不可重入锁,则会导致死锁发生
读写锁
- 有些情况下,对于共享资源读竞争的情况远远多于写竞争,这种情况下对读操作每次都进行加速,是得不偿失的,读写锁就是为了解决这个问题
- 读写锁允许同一时刻被多个读线程访问,但是在写线程访问时,所有的读线程和其他的写线程都会被阻塞,简单可以总结为,读读不互斥,读写互斥,写写互斥
- 对读写锁来说,有一个升级和降级的概念,即当前获得了读锁,想把当前的锁变成写锁,称为升级,反之称为降级,锁的升降级本身也是为了提升性能,通过改变当前锁的性质,避免重复获取锁
协程
协程(Coroutine)又称微线程,纤程,协程可以理解为用户级线程,协程和线程的区别是,线程是抢占式的调度,而协程是协同式的调度,协程避免了无意义的调度,由此可以提高性能
但也因此,程序员必须自己承担调度的责任,同时,协程也失去了标准线程使用多 CPU 的能力,下面是一个使用协程来解决生产者与消费者问题
1 | def produce(c): |
可以看到,使用协程不再需要显式地对锁进行操作
IO 多路复用
IO 多路复用是指内核一旦发现进程指定的一个或者多个 IO 条件准备读取,它就通知该进程,IO 多路复用适用如下场合
- 当客户处理多个描述字时(一般是交互式输入和网络套接口),必须使用
I/O复用 - 当一个客户同时处理多个套接口时,而这种情况是可能的,但很少出现
- 如果一个
TCP服务器既要处理监听套接口,又要处理已连接套接口,一般也要用到I/O复用 - 如果一个服务器即要处理
TCP,又要处理UDP,一般要使用I/O复用 - 如果一个服务器要处理多个服务或多个协议,一般要使用
I/O复用
与多进程和多线程技术相比,I/O 多路复用技术的最大优势是系统开销小,系统不必创建进程或线程,也不必维护这些进程或线程,从而大大减小了系统的开销
常见的 IO 复用实现
select函数(Linux/Windows/BSD)epoll函数(Linux)kqueue函数(BSD/Mac OS X)
第四部分,内存管理基础
主要介绍以下内容
- 程序可执行文件的结构
- 堆和栈
- 内存分配
程序可执行文件的结构
一个程序的可执行文件在内存中的结果,从大的角度可以分为两个部分,只读部分和可读写部分
- 只读部分包括程序代码(
.text)和程序中的常量(.rodata) - 可读写部分(也就是变量)大致可以分成下面几个部分
.data,初始化了的全局变量和静态变量.bss,即Block Started by Symbol,未初始化的全局变量和静态变量Heap,堆,使用malloc,realloc和free函数控制的变量,堆在所有的线程,共享库,和动态加载的模块中被共享使用Stack,栈,函数调用时使用栈来保存函数现场,自动变量(即生命周期限制在某个scope的变量)也存放在栈中
data 和 bss 区
这两个区经常放在一起说,因为他们都是用来存储全局变量和静态变量的,区别在于 data 区存放的是初始化过的,bss 区存放的是没有初始化过的
1 | int val = 3; |
这两个变量的值会一开始被存储在 .text 中(因为值是写在代码里面的),在程序启动时会拷贝到 .data 区中,而不初始化的话,像下面这样则会被放在 bss 区中
1 | static int i; |
静态变量和全局变量
这两个概念都是很常见的概念,又经常在一起使用,很容易造成混淆,全局变量是指在一个代码文件当中,一个变量要么定义在函数中,要么定义在在函数外面,当定义在函数外面时,这个变量就有了全局作用域,成为了全局变量,全局变量不光意味着这个变量可以在整个文件中使用,也意味着这个变量可以在其他文件中使用(external linkage)
当有如下两个文件时
1 | // a.c |
在 Link 过程中会产生重复定义错误,因为有两个全局的 a 变量,Linker 不知道应该使用哪一个,为了避免这种情况,就需要引入静态变量(static),所谓的静态变量指使用 static 关键字修饰的变量,static 关键字对变量的作用域进行了限制,具体的限制如下
- 在函数外定义,全局变量,但是只在当前文件中可见(叫做
internal linkage) - 在函数内定义,全局变量,但是只在此函数内可见(同时在多次函数调用中,变量的值不会丢失)
- 在类中定义(
C++),全局变量,但是只在此类中可见
对于全局变量来说,为了避免上面提到的重复定义错误,我们可以在一个文件中使用 static,另一个不使用,这样使用 static 的就会使用自己的 a 变量,而没有用 static 的会使用全局的 a 变量,当然,最好两个都使用 static 来避免更多可能的命名冲突
需要注意的是,实际上
static跟不可改变没有关系,不可改变的变量使用const关键字修饰,注意不要混淆
程序在内存和硬盘上不同的存在形式
这里我们提到的几个区,是指程序在内存中的存在形式,和程序在硬盘上存储的格式不是完全对应的,程序在硬盘上存储的格式更加复杂,而且是和操作系统有关的,一个比较明显的例子可以帮你区分这个差别
之前我们提到过未定义的全局变量存储在 .bss 区,这个区域不会占用可执行文件的空间(一般只存储这个区域的长度),但是却会占用内存空间,这些变量没有定义,因此可执行文件中不需要存储(也不知道)它们的值,在程序启动过程中,它们的值会被初始化成 0 存储在内存中
栈
- 栈是用于存放本地变量,内部临时变量以及有关上下文的内存区域,程序在调用函数时,操作系统会自动通过压栈和弹栈完成保存函数现场等操作,不需要程序员手动干预
- 栈是一块连续的内存区域,栈顶的地址和栈的最大容量是系统预先规定好的,能从栈获得的空间较小,如果申请的空间超过栈的剩余空间时,例如递归深度过深将提示
stackoverflow - 栈是机器系统提供的数据结构,计算机会在底层对栈提供支持,比如分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高
堆
堆是用于存放除了栈里的东西之外所有其他东西的内存区域,当使用 malloc 和 free 时就是在操作堆中的内存,对于堆来说释放工作由程序员控制,容易产生 memory leak
堆是向高地址扩展的数据结构,是不连续的内存区域,这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址,堆的大小受限于计算机系统中有效的虚拟内存,由此可见,堆获得的空间比较灵活,也比较大
对于堆来讲,频繁的 new 或者 delete 势必会造成内存空间的不连续,从而造成大量的碎片,使程序效率降低,对于栈来讲,则不会存在这个问题,因为栈是先进后出的队列,永远都不可能有一个内存块从栈中间弹出
堆都是动态分配的,没有静态分配的堆,栈有两种分配方式
- 静态分配,是编译器完成的,比如局部变量的分配
- 动态分配,由
alloca函数进行分配,但是栈的动态分配和堆是不同的,他的动态分配是由编译器进行释放,无需我们手工实现
计算机底层并没有对堆的支持,堆则是 C/C++ 函数库提供的,同时由于上面提到的碎片问题,都会导致堆的效率比栈要低
内存分配
- 虚拟地址,是用户编程时将代码(或数据)分成若干个段,每条代码或每个数据的地址由段名称加上段内相对地址构成,这样的程序地址称为虚拟地址
- 逻辑地址,是虚拟地址中,段内相对地址部分称为逻辑地址
- 物理地址,是实际物理内存中所看到的存储地址称为物理地址
- 逻辑地址空间,是在实际应用中,将虚拟地址和逻辑地址经常不加区分,通称为逻辑地址(逻辑地址的集合称为逻辑地址空间)
- 线性地址空间,是
CPU地址总线可以访问的所有地址集合称为线性地址空间 - 物理地址空间,是实际存在的可访问的物理内存地址集合称为物理地址空间
- 内存管理单元(
Memery Management Unit,简称MMU),是实现将用户程序的虚拟地址(逻辑地址)到物理地址映射的CPU中的硬件电路 - 基地址,是在进行地址映射时,经常以段或页为单位并以其最小地址(即起始地址)为基值来进行计算
- 偏移量,是在以段或页为单位进行地址映射时,相对于基地址的地址值
虚拟地址先经过分段机制映射到线性地址,然后线性地址通过分页机制映射到物理地址
虚拟内存
虚拟内存是计算机系统内存管理的一种技术,它使得应用程序认为它拥有连续的可用的内存(一个连续完整的地址空间),而实际上,它通常是被分隔成多个物理内存碎片,还有部分暂时存储在外部磁盘存储器上,在需要时进行数据交换
虚拟内存是由硬件和操作系统自动实现存储信息调度和管理的,调度方式有分页式、段式、段页式三种
第五部分,磁盘与文件
主要介绍以下内容
- 磁盘调度
- 文件系统
- 内存分配
磁盘调度
磁盘访问延迟 = 队列时间 + 控制器时间 + 寻道时间 + 旋转时间 + 传输时间,磁盘调度的目的是减小延迟,其中前两项可以忽略,寻道时间是主要矛盾
磁盘调度算法
FCFS,先进先出的调度策略,这个策略具有公平的优点,因为每个请求都会得到处理,并且是按照接收到的顺序进行处理SSTF(Shortest-seek-time First,最短寻道时间优先),选择使磁头从当前位置开始移动最少的磁盘I/O请求,所以SSTF总是选择导致最小寻道时间的请求- 总是选择最小寻找时间并不能保证平均寻找时间最小,但是能提供比
FCFS算法更好的性能,会存在饥饿现象
- 总是选择最小寻找时间并不能保证平均寻找时间最小,但是能提供比
SCAN,中途不回折,每个请求都有处理机会SCAN要求磁头仅仅沿一个方向移动,并在途中满足所有未完成的请求,直到它到达这个方向上的最后一个磁道,或者在这个方向上没有其他请求为止,由于磁头移动规律与电梯运行相似,SCAN也被称为电梯算法SCAN算法对最近扫描过的区域不公平,因此,它在访问局部性方面不如FCFS算法和SSTF算法好
C-SCAN,直接移到另一端,两端请求都能很快处理- 把扫描限定在一个方向,当访问到某个方向的最后一个磁道时,磁道返回磁盘相反方向磁道的末端,并再次开始扫描,其中
C是Circular(环)的意思
- 把扫描限定在一个方向,当访问到某个方向的最后一个磁道时,磁道返回磁盘相反方向磁道的末端,并再次开始扫描,其中
LOOK和C-LOOK- 釆用
SCAN算法和C-SCAN算法时磁头总是严格地遵循从盘面的一端到另一端,显然,在实际使用时还可以改进,即磁头移动只需要到达最远端的一个请求即可返回,不需要到达磁盘端点 - 这种形式的
SCAN算法和C-SCAN算法称为LOOK和C-LOOK调度(这是因为它们在朝一个给定方向移动前会查看是否有请求)
- 釆用
文件系统
分区表
MBR,支持最大卷为2TB(Terabytes)并且每个磁盘最多有4个主分区(或3个主分区,1个扩展分区和无限制的逻辑驱动器)GPT,支持最大卷为18EB(Exabytes)并且每磁盘的分区数没有上限,只受到操作系统限制(由于分区表本身需要占用一定空间,最初规划硬盘分区时,留给分区表的空间决定了最多可以有多少个分区,IA-64版Windows限制最多有128个分区,这也是EFI标准规定的分区表的最小尺寸,另外,GPT分区磁盘有备份分区表来提高分区数据结构的完整性
RAID 技术
磁盘阵列(Redundant Arrays of Independent Disks,RAID),独立冗余磁盘阵列之。原理是利用数组方式来作磁盘组,配合数据分散排列的设计,提升数据的安全性。
RAID 0,是最早出现的RAID模式,需要2块以上的硬盘,可以提高整个磁盘的性能和吞吐量RAID 0没有提供冗余或错误修复能力,其中一块硬盘损坏,所有数据将遗失
RAID 1,就是镜像,其原理为在主硬盘上存放数据的同时也在镜像硬盘上写一样的数据- 当主硬盘(物理)损坏时,镜像硬盘则代替主硬盘的工作,因为有镜像硬盘做数据备份,所以
RAID 1的数据安全性在所有的RAID级别上来说是最好的 - 但无论用多少磁盘做
RAID 1,仅算一个磁盘的容量,是所有RAID中磁盘利用率最低的
- 当主硬盘(物理)损坏时,镜像硬盘则代替主硬盘的工作,因为有镜像硬盘做数据备份,所以
RAID 2- 这是
RAID 0的改良版,以汉明码(Hamming Code)的方式将数据进行编码后分区为独立的比特,并将数据分别写入硬盘中 - 因为在数据中加入了错误修正码(
ECC,Error Correction Code),所以数据整体的容量会比原始数据大一些,RAID 2最少要三台磁盘驱动器方能运作
- 这是
RAID 3采用Bit-interleaving(数据交错存储)技术,它需要通过编码再将数据比特分割后分别存在硬盘中,而将同比特检查后单独存在一个硬盘中,但由于数据内的比特分散在不同的硬盘上,因此就算要读取一小段数据资料都可能需要所有的硬盘进行工作,所以这种规格比较适于读取大量数据时使用RAID 4,它与RAID 3不同的是它在分区时是以区块为单位分别存在硬盘中,但每次的数据访问都必须从同比特检查的那个硬盘中取出对应的同比特数据进行核对,由于过于频繁的使用,所以对硬盘的损耗可能会提高(块交织技术,Block interleaving)
RAID 2/3/4在实际应用中很少使用
RAID 5,RAID Level 5是一种储存性能、数据安全和存储成本兼顾的存储解决方案,它使用的是Disk Striping(硬盘分区)技术RAID 5至少需要三块硬盘,RAID 5不是对存储的数据进行备份,而是把数据和相对应的奇偶校验信息存储到组成RAID 5的各个磁盘上,并且奇偶校验信息和相对应的数据分别存储于不同的磁盘上RAID 5允许一块硬盘损坏,实际容量Size = (N-1) * min(S1, S2, S3 ... SN)
RAID 6,与RAID 5相比,RAID 6增加第二个独立的奇偶校验信息块,两个独立的奇偶系统使用不同的算法,数据的可靠性非常高,即使两块磁盘同时失效也不会影响数据的使用RAID 6至少需要4块硬盘,实际容量Size = (N-2) * min(S1, S2, S3 ... SN)
RAID 10/01(RAID 1 + 0,RAID 0 + 1),是先镜射再分区数据,再将所有硬盘分为两组,视为是RAID 0的最低组合,然后将这两组各自视为RAID 1运作RAID 01则是跟RAID 10的程序相反,是先分区再将数据镜射到两组硬盘,它将所有的硬盘分为两组,变成RAID 1的最低组合,而将两组硬盘各自视为RAID 0运作- 当
RAID 10有一个硬盘受损,其余硬盘会继续运作,RAID 01只要有一个硬盘受损,同组RAID 0的所有硬盘都会停止运作,只剩下其他组的硬盘运作,可靠性较低,如果以六个硬盘建RAID 01,镜射再用三个建RAID 0,那么坏一个硬盘便会有三个硬盘脱机,因此,RAID 10远较RAID 01常用,零售主板绝大部份支持RAID 0/1/5/10,但不支持RAID 01 RAID 10至少需要4块硬盘,且硬盘数量必须为偶数
常见文件系统
Windows中有FAT,FAT16,FAT32,NTFSLinux中有ext2/3/4,btrfs,ZFSMac OS X中有HFS+
Linux 文件权限
Linux 文件采用 10 个标志位来表示文件权限,如下所示
1 | -rw-r--r-- 1 skyline staff 20B 1 27 10:34 1.txt |
第一个字符一般用来区分文件和目录,其中
d,表示是一个目录,事实上在ext2fs中,目录是一个特殊的文件-,表示这是一个普通的文件l:,表示这是一个符号链接文件,实际上它指向另一个文件b、c,分别表示区块设备和其他的外围设备,是特殊类型的文件s、p,这些文件关系到系统的数据结构和管道,通常很少见到
第 2 ~ 10 个字符当中的每 3 个为一组,左边三个字符表示所有者权限,中间 3 个字符表示与所有者同一组的用户的权限,右边 3 个字符是其他用户的权限
这三个一组共 9 个字符,代表的意义如下
r(Read,读取),对文件而言,具有读取文件内容的权限,对目录来说,具有浏览目录的权限w(Write,写入),对文件而言,具有新增、修改文件内容的权限,对目录来说,具有删除、移动目录内文件的权限x(eXecute,执行),对文件而言,具有执行文件的权限,对目录来说该用户具有进入目录的权限
权限的掩码可以使用十进制数字表示
- 如果可读,权限是二进制的
100,十进制是4 - 如果可写,权限是二进制的
010,十进制是2 - 如果可运行,权限是二进制的
001,十进制是1
具备多个权限,就把相应的 4、2、1 相加就可以了
- 若要
rwx则4 + 2 + 1 = 7 - 若要
rw-则4 + 2 = 6 - 若要
r-x则4 + 1 = 5 - 若要
r--则= 4 - 若要
-wx则2 + 1 = 3 - 若要
-w-则= 2 - 若要
--x则= 1 - 若要
---则= 0
默认的权限可用 umask 命令修改,用法非常简单,只需执行 umask 777 命令,便代表屏蔽所有的权限,因而之后建立的文件或目录,其权限都变成 000,依次类推,通常 root 帐号搭配 umask 命令的数值为 022、027 和 077,普通用户则是采用 002,这样所产生的权限依次为 755、750、700、775
chmod 命令
chmod 命令非常重要,用于改变文件或目录的访问权限,用户用它控制文件或目录的访问权限
该命令有两种用法,一种是包含字母和操作符表达式的文字设定法,另一种是包含数字的数字设定法
- 文字设定法,
chmod [who] [+ | - | =] [mode]文件名- 操作对象
who可是下述字母中的任一个或者它们的组合u,表示用户(user),即文件或目录的所有者g,表示同组(group)用户,即与文件属主有相同组ID的所有用户o,表示其他(others)用户,a,表示所有(all)用户,它是系统默认值
- 操作符号可以是
- 添加某个权限
- 取消某个权限
=赋予给定权限并取消其他所有权限(如果有的话)
- 设置
mode所表示的权限可用下述字母的任意组合r,可读w,可写x,可执行X,只有目标文件对某些用户是可执行的或该目标文件是目录时才追加x属性s,在文件执行时把进程的属主或组ID置为该文件的文件属主,方式u+s设置文件的用户ID位,g+s设置组ID位t,保存程序的文本到交换设备上u,与文件属主拥有一样的权限g,与和文件属主同组的用户拥有一样的权限o,与其他用户拥有一样的权限
- 文件名,以空格分开的要改变权限的文件列表,支持通配符
- 在一个命令行中可给出多个权限方式,其间用逗号隔开,例如
chmod g + r,o + r example使同组和其他用户对文件example有读权限
- 操作对象
- 数字设定法,直接使用数字表示的权限来更改
- 比如
$ chmod 644 mm.txt
- 比如
chgrp 命令
改变文件或目录所属的组,语法为 chgrp [选项] group filename,比如 $ chgrp - R book /opt/local/book,表示改变 /opt/local/book/ 及其子目录下的所有文件的属组为 book
chown 命令
更改某个文件或目录的属主和属组,这个命令也很常用,chown 将指定文件的拥有者改为指定的用户或组,用户可以是用户名或用户 ID,组可以是组名或组 ID,文件是以空格分开的要改变权限的文件列表,支持通配符,语法为 chown [选项] 用户或组文件
例如 root 用户把自己的一个文件拷贝给用户 xu,为了让用户 xu 能够存取这个文件,root 用户应该把这个文件的属主设为 xu,否则用户 xu 无法存取这个文件,比如把文件 shiyan.c 的所有者改为 wang
1 | chown wang shiyan.c |
参考
第一部分,体系结构
第二部分,操作系统
第三部分,并发技术
第四部分,内存管理
第五部分,磁盘与文件



