

最后更新于
2020-01-05
最近在深入学习 Node.js,有涉及到这一部分内容,翻出来重新更新整理一下,主要涉及到浏览器与 Node.js 当中的进程与线程相关知识,建议在阅读本文之前先了解一下 体系结构与操作系统 当中的进程和线程相关概念
Node.js 中的进程
对于操作系统来说,一个任务就是进程(process),比如打开一个浏览器就是启动了一个浏览器进程,打开一个记事本就启动了一个记事本进程,有些进程还不止同时干一件事,比如 word,它可以同时进行打字、拼写检查,打印等,在一个进程的内部,要同时干多件事,就需要同时运行多个子任务,我们把进程内的这些子任务称为线程(thread),由于每个进程至少要干一件事,所以『一个进程至少有一个线程』,当然也可以有多个,也可以多个线程同时执行
简单来说就是,线程是最小的执行单元,而进程由至少一个线程组成
进程是系统进行资源分配和调度的基本单位,是操作系统结构的基础,进程是线程的容器,Node.js 里通过命令行可以开启一个服务进程,多进程就是进程的复制(fork),fork 出来的每个进程都拥有自己的独立空间地址、数据栈,一个进程无法访问另外一个进程里定义的变量、数据结构,只有建立了 IPC 通信(进程间通信技术),进程之间才可数据共享(关于 IPC 通信相关内容可以见文章下方),我们可以通过一个简单的示例来验证一下
1 | const http = require('http') |
打开任务管理器,可以在进程选项当中发现我们刚开启的 Node.js 进程
为什么需要多进程
在展开之前,我们先来来看下面这个 Node.js 的示例,我们实现一个计算耗时过长造成线程阻塞的例子,来了解阻塞所带来的后果
1 | const http = require('http') |
运行完成后可以发现,页面会处于很长时间的空白状态,而执行完成以后会发现,计算耗时会有 13554.335ms 左右(处理器不同可能造成结果有所不同),不过不用担心,在后面我们会使用 child_process.fork 来实现多个进程来处理
Node.js 的线程与进程
Node.js 是 JavaScript 在服务端的运行环境,构建在 Chrome 的 V8 引擎之上,基于事件驱动、非阻塞 I/O 模型,充分利用操作系统提供的异步 I/O 进行多任务的执行,适合于 I/O 密集型的应用场景,因为异步,程序无需阻塞等待结果返回,而是基于回调通知的机制,原本同步模式等待的时间,则可以用来处理其它任务
- 在单核
CPU系统之上一般采用『单进程 + 单线程』的模式来开发 - 在多核
CPU系统之上,可以用过child_process.fork开启多个进程(在v0.8版本之后新增了Cluster来实现多进程架构),即『多进程 + 单线程』模式
不过需要注意的是,开启多进程不是为了解决高并发,而是主要为了解决单进程模式下 Node.js 的 CPU 利用率不足的情况,充分利用多核 CPU 的性能
process
Node.js 中的进程(process)是一个全局对象,无需 require 直接使用,给我们提供了当前进程中的相关信息
process.env,环境变量,例如通过process.env.NODE_ENV获取不同环境项目配置信息process.nextTick,这个在谈及EventLoop时经常为会提到process.pid,获取当前进程idprocess.ppid,当前进程对应的父进程process.cwd(),获取当前进程工作目录process.platform,获取当前进程运行的操作系统平台process.uptime(),当前进程已运行时间,例如pm2守护进程的uptime值- 进程事件,
process.on('uncaughtException', cb)捕获异常信息、process.on('exit', cb)进程退出监听 - 三个标准流,标准输出(
process.stdout)、标准输入(process.stdin)、标准错误输出(process.stderr)
以上仅列举了部分常用到功能点,除了 process 之外,Node.js 还提供了 child_process 模块用来对子进程进行操作,我们下面简单的总结一下
JavaScript是单线程,但是做为宿主环境的Node.js并非是单线程的- 由于单线程原故,一些复杂的、消耗
CPU资源的任务建议不要交给Node.js来处理,当你的业务需要一些大量计算、视频编码解码等CPU密集型的任务,可以采用C语言 Node.js和Nginx均采用事件驱动方式,避免了多线程的线程创建、线程上下文切换的开销,如果业务大多是基于I/O操作,那么你可以选择Node.js来开发
进程创建
Node.js 提供了 child_process 内置模块,用于创建子进程,有四种方式可以选择
child_process.spawn(),适用于返回大量数据,例如图像处理,二进制数据处理child_process.exec(),适用于小量数据,maxBuffer默认值为200 * 1024超出这个默认值将会导致程序崩溃,数据量过大可采用spawnchild_process.execFile(),类似child_process.exec(),区别是不能通过shell来执行,不支持像I/O重定向和文件查找这样的行为child_process.fork(),衍生新的进程,进程之间是相互独立的,每个进程都有自己的V8实例、内存,系统资源是有限的,不建议衍生太多的子进程出来,通长根据系统CPU核心数设置
.exec()、.execFile()、.fork() 底层都是通过 .spawn() 实现的,.exec()、execFile() 额外提供了回调,当子进程停止的时候执行,下面我们就详细的来看看以上几个方法
child_process.spawn(command[, args][, options])
spawn 方法创建一个子进程来执行特定命令,用法与 execFile 方法类似,但是没有回调函数,只能通过监听事件,来获取运行结果,它属于异步执行,适用于子进程长时间运行的情况
1 | var child_process = require('child_process') |
spawn 方法接受两个参数,第一个是可执行文件,第二个是参数数组,spawn 对象返回一个对象,代表子进程,该对象部署了 EventEmitter 接口,它的 data 事件可以监听,从而得到子进程的输出结果,spawn 方法与 exec 方法非常类似,只是使用格式略有区别
1 | child_process.exec(command, [options], callback) |
但是需要区分两者的默认参数不同,spawn 的 options 默认为
1 | { |
exec 的 options 默认为
1 | { |
child_process.exec(command[, options][, callback])
创建一个 shell,然后在 shell 里执行命令,执行完成后,将 stdout、stderr 作为参数传入回调方法
1 | var exec = require('child_process').exec |
不过需要注意的是,如果传入的命令是用户输入的,有可能产生类似 sql 注入的风险,比如
1 | exec('ls hello.txt; rm -rf *', function (error, stdout, stderr) { |
child_process.execFile(file[, args][, options][, callback])
跟 .exec() 类似,不同点在于,没有创建一个新的 shell,至少有两点影响
- 比
child_process.exec()效率高一些 - 一些操作,比如
I/O重定向,文件glob等不支持
1 | var child_process = require('child_process') |
从源码层面来看,exec() 和 execFile() 最大的差别就在于是否创建了 shell,那么可以手动设置 shell,比如下面的代码差不多是等价的
1 | var child_process = require('child_process') |
execFile() 内部最终还是通过 spawn() 实现的,如果没有设置 { shell: '/bin/bash' },那么 spawm() 内部对命令的解析会有所不同,execFile('ls -al .') 会直接报错
child_process.fork(modulePath[, args][, options])
fork 方法直接创建一个子进程来执行脚本,fork('./child.js') 相当于 spawn('node', ['./child.js']),与 spawn 方法不同的是,fork 会在父进程与子进程之间建立一个通信管道,用于进程之间的通信(IPC)
1 | // parent.js |
运行结果如下
1 | message from child: { 'from': 'child' } |
实战
在之前章节当中,我们实现了一个计算耗时的函数,可以发现在 CPU 计算密度大的情况程序会造成阻塞导致后续请求需要等待,不过在了解了多进程相关知识以后,我们下面就可以采用 child_process.fork 方法来进行改写,主要流程有以下几步
- 在进行
cpmpute计算时创建子进程 - 子进程计算完成通过
send方法将结果发送给主进程 - 主进程通过
message监听到信息后处理并退出
1 | // fork_app.js |
Node.js 多进程架构模型
多进程架构解决了单进程、单线程无法充分利用系统多核 CPU 的问题,下面就通过一个示例来了解如何启动一批 Node.js 进程来提供服务
主进程 master.js
代码如下
1 | // master.js |
master.js 作为入口文件,主要处理以下逻辑
- 创建一个
server并监听3000端口 - 根据系统
CPU个数开启多个子进程 - 通过子进程对象的
send方法发送消息到子进程进行通信 - 在主进程中监听了子进程的变化,如果是自杀信号重新启动一个工作进程
- 主进程在监听到退出消息的时候,先退出子进程在退出主进程
工作进程
下面来看看上面我们 fork 的 worker.js,主要逻辑如下
- 创建一个
server对象,注意最开始并没有监听3000端口 - 通过
message事件接收主进程send方法发送的消息 - 监听
uncaughtException事件,捕获未处理的异常,发送关闭信息由主进程重建进程,子进程在链接关闭之后退出
1 | // worker.js |
测试
控制台执行 node master.js 可以看到已成功创建了四个工作进程
1 | $ node master |
打开活动监视器查看我们的进程情况,由于在创建进程时对进程进行了命名,很清楚的看到一个主进程对应多个子进程,如果想要了解更多相关内容可以参考 Egg 官方文档当中的 多进程模型和进程间通讯
守护进程
本章节主要涉及下面几个问题
- 什么是守护进程
- 守护进程的作用
- 如何编写守护进程
守护进程运行在后台不受终端的影响,比如在 Node.js 当中,当我们打开终端执行 node app.js 开启一个服务进程之后,这个终端就会一直被占用,如果关掉终端,服务就会断掉,即前台运行模式,如果采用守护进程进程方式,这个终端在我们使用 node app.js 开启一个服务进程之后,还可以在这个终端上做些别的事情,且不会相互影响
创建步骤
主要有下面四个步骤
- 借助
clild_process中的spawn创建子进程 - 在子进程中创建新会话,在
spawn的第三个参数中,可以设置detached属性,如果该属性为true,则会调用系统函数setsid方法 - 改变子进程工作目录(如:
/或/usr/等),options.cwd指定当前子进程工作目录若不做设置默认继承当前工作目录 - 父进程终止(运行
daemon.unref()退出父进程)
1 | // index.js |
daemon.js 文件里处理逻辑开启一个定时器每 10 秒执行一次,使得这个资源不会退出,同时写入日志到子进程当前工作目录下
1 | // daemon.js |
运行测试
1 | $ node index.js |
打开活动监视器查看,目前只有一个进程 47609,这就是我们需要进行守护的进程,当然,以上只是一个简单的示例,在实际工作中对守护进程的健壮性要求还是很高的,比如进程的异常监听、工作进程管理调度、进程挂掉之后重启等等,推荐阅读 编写守护进程 了解更多
问题汇总
下面是一些在实际使用当中可能会遇到的问题,主要包括以下内容
- 什么是进程和线程?两者之间有什么区别?
- 什么是孤儿进程?
- 创建多进程时,代码里有
app.listen(port)在进行fork时,为什么没有报端口被占用? - 什么是
IPC通信,如何建立IPC通信?什么场景下需要用到IPC通信? - 父进程与子进程是如何通信的?
Node.js是单线程还是多线程?- 如何实现一个简单的命令行交互程序?
- 如何让一个
js文件在Linux下成为一个可执行命令程序? - 进程的当前工作目录是什么? 有什么作用?
- 多进程或多个
Web服务之间的状态共享问题?
下面我们就一个一个来看
什么是进程和线程?两者之间有什么区别?
之前已经介绍过了,这里小小的总结一下
- 关系
- 进程中包含着至少一个线程
- 在进程创建之初,就会包含一个线程,这个线程会根据需要,调用系统库函数去创建其他线程
- 但需要注意的是,这些线程之间是没有层级关系的,他们之间协同完成工作,在整个进程完成工作之后,其中的线程会被销毁,释放资源
- 共性
- 都包含三个状态,就绪、阻塞、运行
- 阻塞就是资源未到位,等待资源中
- 就绪,就是资源到位了,但是
CPU未到位,还在运行其他
什么是孤儿进程?
父进程创建子进程之后,父进程退出了,但是父进程对应的一个或多个子进程还在运行,这些子进程会被系统的 init 进程收养,对应的进程 ppid 为 1,这就是孤儿进程
1 | // master.js |
在控制台进行测试,输出当前工作进程 pid 和 父进程 ppid
1 | $ node master |
由于在 master.js 里退出了父进程,活动监视器所显示的也就只有工作进程,再次验证,打开控制台调用接口,可以看到工作进程 32971 对应的 ppid 为 1(为 init 进程),此时已经成为了孤儿进程
1 | $ curl http://127.0.0.1:3000 |
创建多进程时,代码里有 app.listen(port) 在进行 fork 时,为什么没有报端口被占用?
我们先来看一个端口被占用的情况
1 | // master.js |
以上代码示例,控制台执行 node master.js 只有一个 worker 可以监听到 3000 端口,其余将会抛出 Error: listen EADDRINUSE :::3000 错误,那么多进程模式下怎么实现多端口监听呢?
通过上面的多进程当中的示例可以发现,在这种情况下就可以通过句柄传递来实现多端口监听,当父子进程之间建立 IPC 通道之后,通过子进程对象的 send 方法发送消息,第二个参数 sendHandle 就是句柄,可以是 TCP 套接字、TCP 服务器、UDP 套接字等,为了解决上面多进程端口占用问题,我们将主进程的 socket 传递到子进程,修改代码
1 | //master.js |
验证一番,控制台执行 node master.js 以下结果是我们预期的,多进程端口占用问题已经被解决了
1 | $ node master.js |
关于多进程端口占用问题,可以参考 通过源码解析 Node.js 中 cluster 模块的主要功能实现
什么是 IPC 通信,如何建立 IPC 通信?什么场景下需要用到 IPC 通信?
IPC(Inter-process communication),即进程间通信技术,由于每个进程创建之后都有自己的独立地址空间,实现 IPC 的目的就是为了进程之间资源共享访问,实现 IPC 的方式有多种方式,例如管道、消息队列、信号量、Domain Socket 等,在 Node.js 当中是通过 pipe 来实现,我们先来看一个未使用 IPC 的情况
1 | // pipe.js |
控制台执行 node pipe.js,输出主进程 id、子进程 id,但是子进程 worker.js 的信息并没有在控制台打印,原因是新创建的子进程有自己的 stdio 流
1 | $ node pipe.js |
下面我们再来创建一个父进程和子进程之间传递消息的 IPC 通道实现输出信息的示例,通过修改 pipe.js 让子进程的 stdio 和当前进程的 stdio 之间建立管道链接,还可以通过 spawn() 方法的 stdio 选项建立 IPC 机制
1 | // pipe.js |
再次执行 node pipe.js,可以发现 worker.js 的信息也打印了出来
1 | $ 42473 42474 |
父进程与子进程是如何通信的?
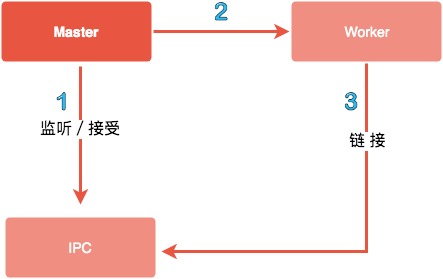
父进程在创建子进程之前会先去创建 IPC 通道并一直监听该通道,之后开始创建子进程并通过环境变量(NODE_CHANNEL_FD)的方式将 IPC 频道的文件描述符传递给子进程,子进程启动时根据传递的文件描述符去链接 IPC 通道,从而建立父子进程之间的通信机制
Node.js 是单线程还是多线程?
JavaScript 是单线程的,但是做为其在服务端运行环境的 Node.js 并非是单线程的,至于 JavaScript 为什么是单线程?这个问题需要从浏览器说起,在浏览器环境中对于 DOM 的操作,不可能存在多个线程来对同一个 DOM 同时操作,那也就意味着对于 DOM 的操作只能是单线程,避免 DOM 渲染冲突,而在浏览器环境中 UI 渲染线程和 JavaScript 执行引擎是互斥的,一方在执行时都会导致另一方被挂起,这是由 JavaScript 引擎所决定的
如何实现一个简单的命令行交互程序?
可以采用子进程 child_process 的 spawn 方法,如下所示
1 | const spawn = require('child_process').spawn |
运行
1 | $ node execfile |
如何让一个 js 文件在 Linux 下成为一个可执行命令程序?
- 新建
hello.js文件,头部须加上#!/usr/bin/env node,表示当前脚本使用Node.js进行解析 - 赋予文件可执行权限
chmod + x chmod + x /${dir}/hello.js,目录自定义 - 在
/usr/local/bin目录下创建一个软链文件sudo ln -s /${dir}/hello.js /usr/local/bin/hello,文件名就是我们在终端使用的名字 - 终端执行
hello相当于输入node hello.js
1 | #!/usr/bin/env node |
终端测试
1 | $ hello |
进程的当前工作目录是什么? 有什么作用?
进程的当前工作目录可以通过 process.cwd() 命令获取,默认为当前启动的目录,如果是创建子进程则继承于父进程的目录,可通过 process.chdir() 命令重置,例如通过 spawn 命令创建的子进程可以指定 cwd 选项设置子进程的工作目录,有什么作用?例如通过 fs 模块来读取文件,如果设置为相对路径则相对于当前进程启动的目录进行查找,所以启动目录设置有误的情况下将无法得到正确的结果,还有一种情况程序里引用第三方模块也是根据当前进程启动的目录来进行查找的
1 | // 设置当前进程目录 |
多进程或多个 Web 服务之间的状态共享问题?
多进程模式下各个进程之间是相互独立的,例如用户登陆之后 Session 的保存,如果保存在服务进程里,那么如果我有 4 个工作进程,每个进程都要保存一份这是没必要的,如果服务重启了数据也会丢失,多个 Web 服务也是一样的,还会出现我在 A 机器上创建了 Session,当负载均衡分发到 B 机器上之后还需要在创建一份,一般的做法是通过 Redis 或者数据库来做数据共享



