

最近在复习计算机网络相关知识,因为在复习过程中发现博客当中很多关于 HTTP 的内容都是东一块西一块的混杂在一起,没有形成体系,所以干脆就将之前的全部内容提取出来,然后重新的整理一遍,在借助一些书籍从 HTTP 诞生之时开始重新的梳理一遍其相关内容,也算是从零开始从新学习 HTTP
其实主要目的还是了解一下 HTTP、TCP/IP、HTTPS 等相关概念到底是什么,又是用来做什么的,这里因为 HTTP 相关内容篇幅较长,所以我们使用一张思维导图简单的汇总一下,如下(详细信息可以参考左侧目录)
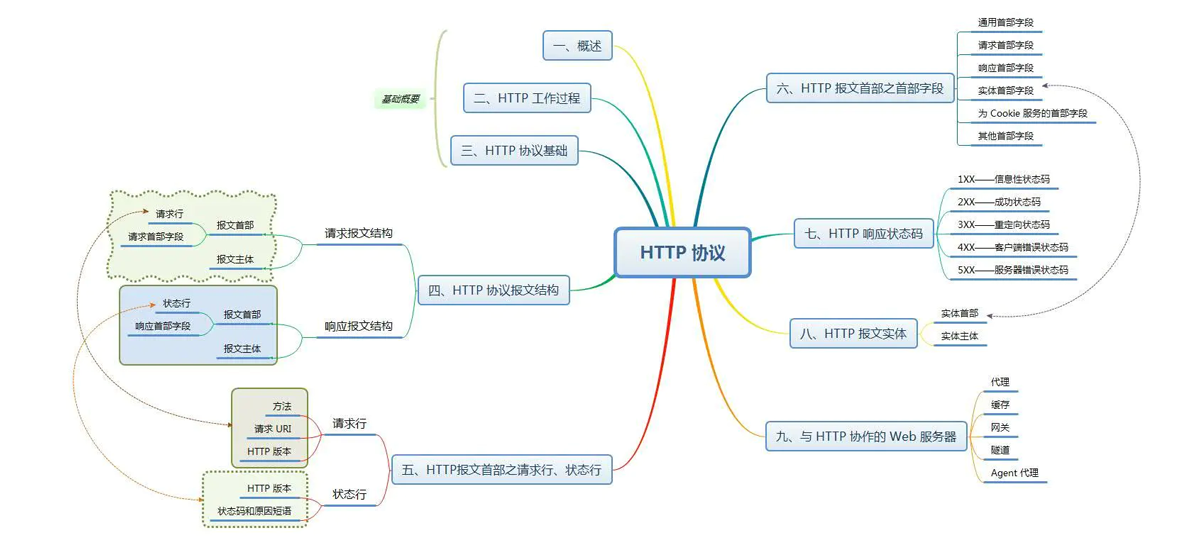
这里需要注意,因为相较于
HTTP协议,TCP/IP协议的相关内容也是非常之多的,所以在本章当中我们只简单的介绍一下TCP/IP相关基本内容,更为详细的内容会在后续深入学习后再来进行补充
HTTP 概述
1989 年 3 月,当时的互联网还只属于少数人,在这一互联网的黎明期,HTTP 诞生了,CERN(欧洲核子研究组织)的蒂姆·伯纳斯博士提出了一种能让远隔两地的研究者们共享知识的设想,
最初设想的基本理念是借助多文档之间相互关联形成的超文本(HyperText),连成可相互参阅的 WWW(World Wide Web,万维网),针对于此提出了三项 WWW 构建技术,分别是
- 把
SGML(Standard Generalized Markup Language,标准通用标记语言)作为页面的文本标记语言的HTML(HyperText Markup Language,超文本标记语言) - 作为文档传递协议的
HTTP - 指定文档所在地址的
URL(Uniform Resource Locator,统一资源定位符)
WWW 这一名称,是 Web 浏览器当年用来浏览超文本的客户端应用程序时的名称,现在则用来表示这一系列的集合,也可简称为 Web
发展
1990 年 11 月,CERN 成功研发了世界上第一台 Web 服务器和 Web 浏览器,1990 年,大家针对 HTML/1.0 草案进行了讨论,因 HTML/1.0 中存在多处模糊不清的部分,草案被直接废弃了,接着从 1993 年开始,各公司之间爆发的浏览器大战就没有停息过,在这场浏览器供应商之间的竞争中,他们不仅对当时发展中的各种 Web 标准化视而不见,还屡次出现新增功能没有对应说明文档的情况,而在此过程当中,HTTP 的发展则是驻足不前的,各版本情况如下
HTTP/0.9
HTTP 于 1990 年问世,那时的 HTTP 并没有作为正式的标准被建立,现在的 HTTP 其实含有 HTTP/1.0 之前版本的意思,因此被称为 HTTP/0.9
HTTP/1.0
HTTP 正式作为标准被公布是在 1996 年的 5 月,版本被命名为 HTTP/1.0,并记载于 RFC1945,虽说是初期标准,但该协议标准至今仍被广泛使用在服务器端,地址如下
RFC1945 - Hypertext Transfer Protocol - HTTP/1.0
HTTP/1.1
1997 年 1 月公布的 HTTP/1.1 是目前主流的 HTTP 协议版本,当初的标准是 RFC2068,之后发布的修订版 RFC2616 就是当前的最新版本,地址如下
RFC2616 - Hypertext Transfer Protocol - HTTP/1.1
可见,作为 Web 文档传输协议的 HTTP,它的版本几乎没有更新(关于 HTTP/2,HTTP/3 相关知识我们会在后面进行介绍)
网络基础 TCP/IP
为了理解 HTTP,我们有必要事先了解一下 TCP/IP 协议族,通常使用的网络(包括互联网)是在 TCP/IP 协议族的基础上运作的,而 HTTP 属于它内部的一个子集,区别如下
TPC/IP协议是传输层协议,主要解决数据如何在网络中传输- 而
HTTP是应用层协议,主要解决如何包装数据
计算机与网络设备要相互通信,双方就必须基于相同的方法,比如如何探测到通信目标、由哪一边先发起通信、使用哪种语言进行通信、怎样结束通信等规则都需要事先确定,不同的硬件、操作系统之间的通信,所有的这一切都需要一种规则,而我们就把这种规则称为协议(protocol),协议中存在各式各样的内容,从电缆的规格到 IP 地址的选定方法、寻找异地用户的方法、双方建立通信的顺序,以及 Web 页面显示需要处理的步骤,等等
像这样把与互联网相关联的协议集合起来总称为 TCP/IP,TCP/IP 协议不仅仅指的是 TCP 和 IP 两个协议,而是指一个由 FTP、SMTP、TCP、UDP、IP 等协议构成的协议簇,只是因为在 TCP/IP 协议中 TCP 协议和 IP 协议最具代表性,所以被称为 TCP/IP 协议
一个比较简单的记忆方式,我们可以把
IP想像成一种高速公路,它允许其它协议在上面行驶,TCP和UDP等是高速公路上的卡车,它们携带的货物就是像HTTP,文件传输协议FTP这样的协议
网络模型划分
我们在做开发的过程当中,常常会听说到各种协议,当前存在三种比较流行的划分网络模型的方式,如下
OSI七层模型TCP/IP四层模型- 五层模型
对应如下图
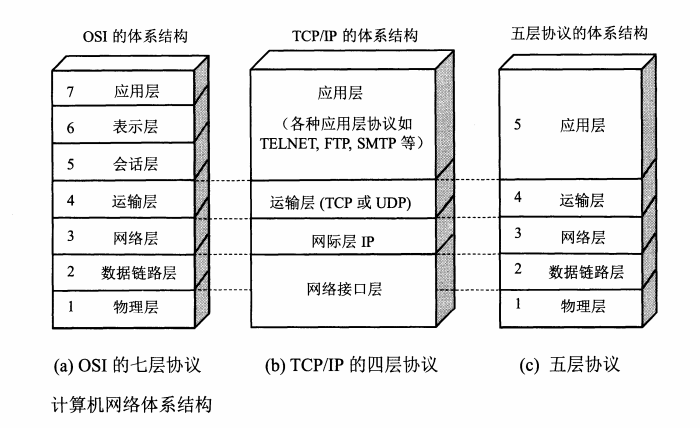
但是这里我们主要介绍
TCP/IP四层模型,关于其他部分只做简单介绍,如果想要了解更多可以另行查阅相关书籍或文章
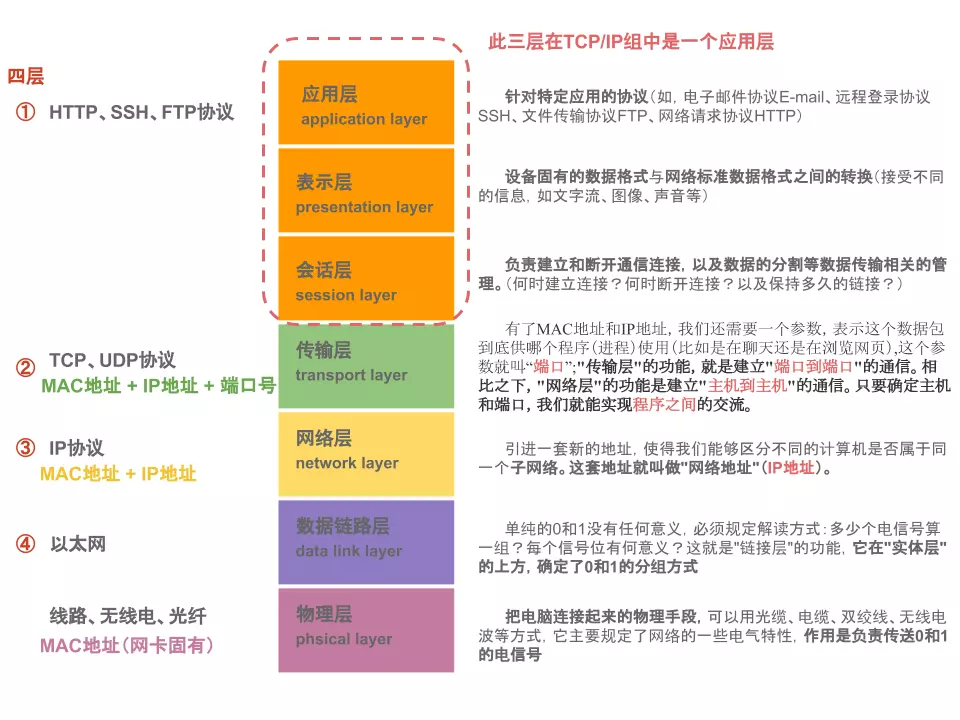
OSI 七层模型
OSI(Open System Interconnection,开放系统互连)七层网络模型称为开放式系统互联参考模型 ,是一个逻辑上的定义,一个规范,它把网络从逻辑上分为了七层,每一层都有相关、相对应的物理设备,比如路由器,交换机等,OSI 七层模型是一种框架性的设计方法,建立七层模型的主要目的是为解决异种网络互连时所遇到的兼容性问题,其主要的功能使就是帮助不同类型的主机实现数据传输,它的最大优点是将服务、接口和协议这三个概念明确地区分开来,通过七个层次化的结构模型使不同的系统不同的网络之间实现可靠的通讯,如下图
TCP/IP 四层模型
TCP/IP 和 OSI 模型组并不能精确的匹配,但是我们可以尽可能的参考 OSI 模型并在其中找到 TCP/IP 的对应位置,OSI 模型到 TCP/IP 模型映射关系,通常人们认为 OSI 模型最上面三层(应用层、表示层、会话层)在 TCP/IP 中是一个应用层,由于 TCP/IP 有一个相对比较弱的会话层,由 TCP 和 RTP 下的打开和关闭连接组成,并在 TCP/UDP 下的各种应用提供不同的端口号,这些功能被单个的应用程序添加
那么 TCP/IP 四层模型跟 OSI 模型有什么不一样呢?
OSI 是一个完整的、完善的宏观理论模型,而 TCP/IP 模型,更加侧重的是互联网通信核心(也是就是围绕 TCP/IP 协议展开的一系列通信协议)的分层,因此它不包括物理层,以及其他一些不想干的协议,其次之所以说他是参考模型,是因为他本身也是 OSI 模型中的一部分,因此参考 OSI 模型对其进行分层
五层模型
五层体系结构包括应用层、运输层、网络层、数据链路层和物理层,五层协议只是 OSI 和 TCP/IP 的综合,实际应用还是 TCP/IP 的四层结构,它的意义其实是为了方便学习计算机网络原理而采用的,综合了 OSI 七层模型和 TCP/IP 的四层模型而得到的五层模型
TCP/IP 的分层管理
TCP/IP 协议族里重要的一点就是分层,TCP/IP 协议族按层次分别分为以下四层,即应用层、传输层、网络层和数据链路层,把 TCP/IP 层次化是有好处的,比如,如果互联网只由一个协议统筹,某个地方需要改变设计时,就必须把所有部分整体替换掉,而分层之后只需把变动的层替换掉即可,把各层之间的接口部分规划好之后,每个层次内部的设计就能够自由改动了
值得一提的是,层次化之后,设计也变得相对简单了,处于应用层上的应用可以只考虑分派给自己的任务,而不需要弄清对方在地球上哪个地方、对方的传输路线是怎样的、是否能确保传输送达等问题,TCP/IP 协议族各层的作用如下
| 名称 | 释义 |
|---|---|
| 应用层 | 应用层决定了向用户提供应用服务时通信的活动,TCP/IP 协议族内预存了各类通用的应用服务,比如 FTP 和 DNS 服务就是其中两类,HTTP 协议也处于该层 |
| 传输层 | 传输层对上层应用层,提供处于网络连接中的两台计算机之间的数据传输,在传输层有两个性质不同的协议 TCP 和 UDP |
| 网络层(又名网络互连层) | 网络层用来处理在网络上流动的数据包,数据包是网络传输的最小数据单位,该层规定了通过怎样的路径(所谓的传输路线)到达对方计算机,并把数据包传送给对方,与对方计算机之间通过多台计算机或网络设备进行传输时,网络层所起的作用就是在众多的选项内选择一条传输路线 |
| 链路层(又名数据链路层,网络接口层) | 用来处理连接网络的硬件部分,包括控制操作系统、硬件的设备驱动、NIC(网络适配器),及光纤等物理可见部分(还包括连接器等一切传输媒介),硬件上的范畴均在链路层的作用范围之内 |
TCP/IP 通信传输流
利用 TCP/IP 协议族进行网络通信时,会通过分层顺序与对方进行通信,发送端从应用层往下走,接收端则往应用层往上走
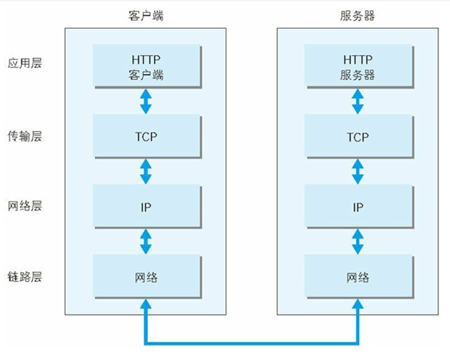
我们用 HTTP 举例来说明,首先作为发送端的客户端在应用层(HTTP 协议)发出一个想看某个 Web 页面的 HTTP 请求,接着为了传输方便,在传输层(TCP 协议)把从应用层处收到的数据(HTTP 请求报文)进行分割,并在各个报文上打上标记序号及端口号后转发给网络层
在网络层(IP 协议)增加作为通信目的地的 MAC 地址后转发给链路层,这样一来发往网络的通信请求就准备齐全了,接收端的服务器在链路层接收到数据,按序往上层发送,一直到应用层,当传输到应用层,才能算真正接收到由客户端发送过来的 HTTP 请求
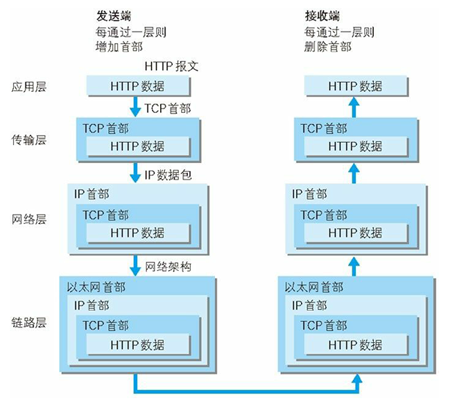
发送端在层与层之间传输数据时,每经过一层时必定会被打上一个该层所属的首部信息,反之接收端在层与层传输数据时,每经过一层时会把对应的首部消去,这种把数据信息包装起来的做法称为封装(encapsulate)
IP、TCP 和 DNS
下面我们来看看在 TCP/IP 协议族中与 HTTP 密不可分的三个协议 IP、TCP 和 DNS
负责传输的 IP 协议
按层次分,IP(Internet Protocol)网际协议位于网络层,它的作用是把各种数据包传送给对方,而要保证确实传送到对方那里,则需要满足各类条件,其中两个重要的条件是 IP 地址和 MAC 地址(Media Access Control Address)(需要注意别把 IP 和 IP 地址搞混淆,IP 其实是一种协议的名称)
IP地址指明了节点被分配到的地址,它可以和MAC地址进行配对,并且是可以变换的,而且IP间的通信依赖MAC地址MAC地址是指网卡所属的固定地址,但MAC地址基本上不会更改
在网络上,通常是经过多台计算机和网络设备中转才能连接到对方,而在进行中转时,会利用下一站中转设备的 MAC 地址来搜索下一个中转目标,这时会采用 ARP 协议(Address Resolution Protocol),ARP 是一种用以解析地址的协议,根据通信方的 IP 地址就可以反查出对应的 MAC 地址
其实简单来说就是需要借助
ARP协议将目标主机的IP地址转换为对应主机的MAC地址才能进行通信
下面我们来简单的看一下 ARP 协议的工作原理,它主要的作用是为了从网络层的 IP 地址,解析出在数据链路层使用的硬件地址,但是需要注意的是,ARP 解决的是同一局域网上的主机和路由器的 IP 地址和硬件地址的映射问题,它的工作原理是下面这样的
- 每一台主机都设有一个
ARP告诉缓存,里面有本局域网上的各个主机和路由器的IP地址到硬件地址的映射,当A要向本局域网上的B发送IP数据报时,则A先查看ARP高速缓存中有无B的IP地址- 如果有,则就在
ARP高速缓存中查出该IP地址的硬件地址,把这个硬件地址写入MAC帧,再通过局域网将MAC帧发往此硬件地址 - 如果没有,则
ARP向本局域网广播(请求分组是广播,响应分组是单播)发送一个ARP请求分组,表明自己的IP地址和硬件地址以及要寻找的IP地址,B接收到请求分组后,收下并且向A发送相应分组,其余主机不做相应,A收到B的相应分组后再进行常规的数据传输
- 如果有,则就在
ARP 对每一个映射地址的项目都设有生存时间(例如 10 - 20 分钟),这是为了防止该局域网中某些主机的硬件地址发生改变的情况
确保可靠性的 TCP 协议
按层次分,TCP 位于传输层,提供可靠的字节流服务,所谓的字节流服务(Byte Stream Service)是指为了方便传输,将大块数据分割成以报文段(segment)为单位的数据包进行管理,而可靠的传输服务是指,能够把数据准确可靠地传给对方
TCP 协议为了更容易传送大数据才把数据分割,而且 TCP 协议能够确认数据最终是否送达到对方,为了准确无误地将数据送达目标处,TCP 协议采用了三次握手(three way handshaking)策略,用 TCP 协议把数据包送出去后,TCP 不会对传送后的情况置之不理,它一定会向对方确认是否成功送达
握手过程中使用了 TCP 的标志 SYN(synchronize)和 ACK(acknowledgement),发送端首先发送一个带 SYN 标志的数据包给对方,接收端收到后,回传一个带有 SYN/ACK 标志的数据包以示传达确认信息,最后发送端再回传一个带 ACK 标志的数据包代表握手结束,若在握手过程中某个阶段莫名中断,TCP 协议会再次以相同的顺序发送相同的数据包
负责域名解析的 DNS 服务
DNS(Domain Name System)服务是和 HTTP 协议一样位于应用层的协议,它提供域名到 IP 地址之间的解析服务,用户通常使用主机名或域名来访问对方的计算机,而不是直接通过 IP 地址访问,但要让计算机去理解名称,相对而言就变得困难了,因为计算机更擅长处理一长串数字,为了解决上述的问题,DNS 服务应运而生,DNS 协议提供通过域名查找 IP 地址,或逆向从 IP 地址反查域名的服务
这里我们就稍微深入一些,来看看 DNS 如何工作的,我们先从查询过程开始看起
查询过程
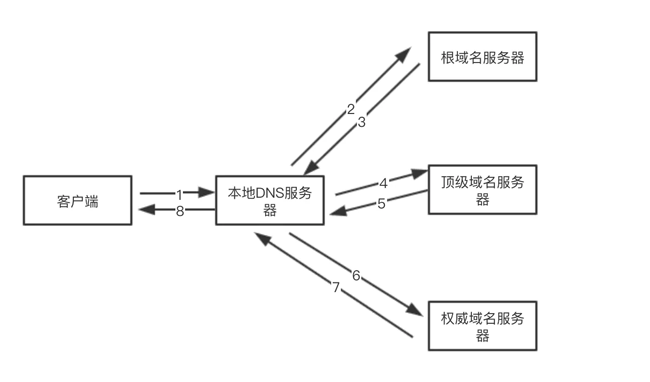
它的查询过程可以如下图所示

这里我们假设 m.xyz.com 需要查找 y.abc.com 的 IP 地址,具体流程是下面这样的
- 主机
m.xyz.com向本地域名服务器进行『递归查询』 - 本地域名服务器『迭代查询』,先向一个根域名服务器查询
- 根域名服务器告诉本地域名服务器,下一步应该向顶级域名服务器
dns.com查询 - 顶级域名服务器
dns.com告诉本地域名服务器,下一步查找权限域名服务器dns.adc.com - 本地域名服务器向权限域名服务器发起查询,权限域名服务器告诉本地域名服务器所需的
IP地址,本地域名服务器在告诉给本地主机
上图展示了 DNS 在本地 DNS 服务器是如何查询的,一般向本地 DNS 服务器发送请求是递归查询的,但是本地 DNS 服务器向其他域名服务器请求的过程是迭代查询的过程,如下
这里要注意区分两者的区别
- 递归查询指的是查询请求发出后,域名服务器代为向下一级域名服务器发出请求,最后向用户返回查询的最终结果,使用递归查询,用户只需要发出一次查询请求
- 迭代查询指的是查询请求后,域名服务器返回单次查询的结果,下一级的查询由用户自己请求,使用迭代查询,用户需要发出多次的查询请求
所以一般而言,主机向本地域名服务器查询时一般使用『递归查询』,而本地 DNS 服务器向其他域名服务器请求的过程是『迭代查询』的过程
这里我们在简单的补充一些关于域名服务器的分类(也就是上图当中右侧部分),如下
- 根域名服务器,最高层也是最重要的域名服务器,所有的根域名服务器都知道所有的顶级域名服务器的域名地址和
IP地址,例如a.rootserver.net - 顶级域名服务器,这些域名服务器负责管理在该顶级域名服务器上注册的所有的二级域名,例如
com - 权限域名服务器,负责一个区的域名服务器,如果当前权限域名服务器不能给出所需的
IP地址,则返回客户应该找哪一个权限服务器 - 本地域名服务器,本地
DNS一般是指你电脑上网时IPv4或者IPv6设置中填写的那个DNS,这个有可能是手工指定的或者是DHCP自动分配的,当一台主机发送DNS请求报文时,这个查询报文就发送给本地域名服务器
DNS 缓存
在一个请求中,当某个 DNS 服务器收到一个 DNS 应答后,它能够将应答中的信息缓存在本地存储器中(返回的资源记录中的 TTL 代表了该条记录的缓存的时间)
DNS 实现负载平衡
首先我们得清楚 DNS 是可以用于在冗余的服务器上实现负载平衡,这是因为一般的大型网站使用多台服务器提供服务,因此一个域名可能会对应多个服务器地址,举个例子来说
当用户发起网站域名的
DNS请求的时候,DNS服务器返回这个域名所对应的服务器IP地址的集合在每个应答中,会循环这些IP地址的顺序,用户一般会选择排在前面的地址发送请求,以此将用户的请求均衡的分配到各个不同的服务器上,这样来实现负载均衡
UDP
在这里我们简单的了解一下经常与 TCP 同时提到的 UDP 协议,UDP 协议全称是用户数据报协议,在网络中它与 TCP 协议一样用于处理数据包,是一种无连接的协议,在 OSI 模型中,在第四层传输层,处于 IP 协议的上一层,UDP 有不提供数据包分组、组装和不能对数据包进行排序的缺点,也就是说当报文发送之后,是无法得知其是否安全完整到达的,它有以下几个特点
- 面向无连接
- 首先
UDP是不需要和TCP一样在发送数据前进行三次握手建立连接的,想发数据就可以开始发送了,并且也只是数据报文的搬运工,不会对数据报文进行任何拆分和拼接操作,具体来说就是 - 在发送端,应用层将数据传递给传输层的
UDP协议,UDP只会给数据增加一个UDP头标识下是UDP协议,然后就传递给网络层了 - 在接收端,网络层将数据传递给传输层,
UDP只去除IP报文头就传递给应用层,不会任何拼接操作
- 首先
- 有单播,多播,广播的功能
UDP不止支持一对一的传输方式,同样支持一对多,多对多,多对一的方式,也就是说UDP提供了单播,多播,广播的功能
UDP是面向报文的- 发送方的
UDP对应用程序交下来的报文,在添加首部后就向下交付IP层,UDP对应用层交下来的报文,既不合并,也不拆分,而是保留这些报文的边界,因此,应用程序必须选择合适大小的报文
- 发送方的
- 不可靠性
- 首先不可靠性体现在无连接上,通信都不需要建立连接,想发就发,这样的情况肯定不可靠,并且收到什么数据就传递什么数据,并且也不会备份数据,发送数据也不会关心对方是否已经正确接收到数据了
- 再者网络环境时好时坏,但是
UDP因为没有拥塞控制,一直会以恒定的速度发送数据,即使网络条件不好,也不会对发送速率进行调整,这样实现的弊端就是在网络条件不好的情况下可能会导致丢包,但是优点也很明显,在某些实时性要求高的场景(比如电话会议)就需要使用UDP而不是TCP
- 头部开销小,传输数据报文时是很高效的
UDP头部包含了以下几个数据- 两个十六位的端口号,分别为源端口(可选字段)和目标端口
- 整个数据报文的长度
- 整个数据报文的检验和(
IPv4可选 字段),该字段用于发现头部信息和数据中的错误
- 因此
UDP的头部开销小,只有八字节,相比TCP的至少二十字节要少得多,在传输数据报文时是很高效的
HTTP 协议
HTTP 协议(HyperText Transfer Protocol,超文本传输协议)定义了浏览器怎样向万维网服务器请求万维网文档,以及服务器怎样把文档传送给浏览器,从层次的角度看,HTTP 是面向(transaction-oriented)应用层协议,它是万维网上能够可靠地交换文件(包括文本,声音,图像等各种多媒体文件)的重要基础,也是 Web 联网的基础
客户机需要通过 HTTP 协议传输所要访问的超文本信息,HTTP 包含命令和传输信息,不仅可用于 Web 访问,也可以用于其他因特网/内联网应用系统之间的通信,从而实现各类应用资源超媒体访问的集成
我们在浏览器的地址栏里输入的网站地址叫做 URL(Uniform Resource Locator,统一资源定位符),当你在浏览器的地址框中输入一个 URL 或是单击一个超级链接时,URL 就确定了要浏览的地址,浏览器通过超文本传输协议(HTTP),将 Web 服务器上站点的网页代码提取出来,并翻译成我们最终所见到的网页
HTTP 工作流程
我们以下图为例,先来简单的梳理一下 HTTP 的整个工作流程,其实简单来说,就是请求与响应的过程
HTTP 通信机制是在一次完整的 HTTP 通信过程中,客户端与服务器之间将完成下列七个步骤
1、建立 TCP 连接
在 HTTP 工作开始之前,客户端首先要通过网络与服务器建立连接,该连接是通过 TCP 来完成的(即著名的 TCP/IP 协议族),HTTP 是比 TCP 更高层次的应用层协议(可以参考上面的网络模型划分),根据规则,只有低层协议建立之后,才能进行高层协议的连接,因此首先要建立 TCP 连接,一般 TCP 连接的端口号是 80
2、客户端向服务器发送请求命令
一旦建立了 TCP 连接,客户端就会向服务器发送请求命令,例如
1 | GET /index.html HTTP/1.1 |
3、客户端发送请求头信息
客户端发送其请求命令之后,还要以头信息的形式向服务器发送一些别的信息,之后客户端发送了一空白行来通知服务器,它已经结束了该头信息的发送
4、服务器应答
客户端向服务器发出请求后,服务器会客户端返回响应,例如
1 | HTTP/1.1 200 OK |
响应报文基本上由协议版本、状态码(表示请求成功或失败的数字代码)、用以解释状态码的原因短语、可选的响应首部字段以及实体主体构成
5、服务器返回响应头信息
正如客户端会随同请求发送关于自身的信息一样,服务器也会随同响应向用户发送关于它自己的数据及被请求的文档
6、服务器向客户端发送数据
服务器向客户端发送头信息后,它会发送一个空白行来表示头信息的发送到此为结束,接着它就以 Content-Type 响应头信息所描述的格式发送用户所请求的实际数据
7、服务器关闭 TCP 连接
一般情况下,一旦服务器向客户端返回了请求数据,它就要关闭 TCP 连接,然后如果客户端或者服务器在其头信息加入了 Connection: keep-alive,TCP 连接在发送后将仍然保持打开状态,于是客户端可以继续通过相同的连接发送请求,保持连接节省了为每个请求建立新连接所需的时间,还节约了网络带宽
HTTP 协议特点
这里主要涉及到的是一些关于 HTTP 协议特点的基础知识
通过请求和响应的交换达成通信
应用 HTTP 协议时,必定是一端担任客户端角色,另一端担任服务器端角色,仅从一条通信线路来说,服务器端和客服端的角色是确定的,HTTP 协议规定,请求从客户端发出,最后服务器端响应该请求并返回,换句话说,肯定是先从客户端开始建立通信的,服务器端在没有接收到请求之前不会发送响应
HTTP 是不保存状态的协议
HTTP 是一种无状态协议,协议自身不对请求和响应之间的通信状态进行保存,也就是说在 HTTP 这个级别,协议对于发送过的请求或响应都不做持久化处理,这是为了更快地处理大量事务,确保协议的可伸缩性,而特意把 HTTP 协议设计成如此简单的
可是随着 Web 的不断发展,我们的很多业务都需要对通信状态进行保存,于是我们引入了 Cookie 技术,有了 Cookie 再用 HTTP 协议通信,就可以管理状态了
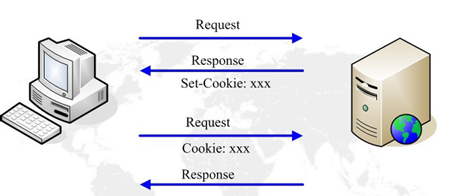
使用 Cookie 的状态管理
Cookie 技术通过在请求和响应报文中写入 Cookie 信息来控制客户端的状态,Cookie 会根据从服务器端发送的响应报文内的一个叫做 Set-Cookie 的首部字段信息,通知客户端保存Cookie,当下次客户端再往该服务器发送请求时,客户端会自动在请求报文中加入 Cookie 值后发送出去,服务器端发现客户端发送过来的 Cookie 后,会去检查究竟是从哪一个客户端发来的连接请求,然后对比服务器上的记录,最后得到之前的状态信息
请求 URI 定位资源
HTTP 协议使用 URI 定位互联网上的资源,正是因为 URI 的特定功能,在互联网上任意位置的资源都能访问到,但是我们在平时听到或者见到更多的应该是 URL(Uniform Resource Locator,统一资源定位符),那么这两者有什么区别呢?
用大白话来说就是,URI 是抽象的定义,不管用什么方法表示,只要能定位一个资源,就叫 URI,本来设想的的使用两种方法定位,URL(地址定位)和 URN(名称定位),只是后来 URN 没流行起来,导致几乎目前所有的 URI 都是 URL,所以这里我们就以 URL 为例,如下所示
1 | 协议 IP 地址 端口 资源的具体位置 |
- 第一部分是协议(或称为服务方式)
- 第二部分是存有该资源的主机
IP地址(有时也包括端口号) - 第三部分是主机资源的具体位置(如目录和文件名等)
- 第一部分和第三部分之间用
'://'符号隔开,第二部分和第三部分用'/'符号分隔,第一部分和第二部分是不可缺少的,第三部分有时也可以省略
告知服务器意图的 HTTP 方法
也就是 HTTP/1.1 当中可使用的方法,如下图

这里有几个需要注意的地方
HTTP/1.1的DELETE方法本身和PUT方法一样不带验证机制,所以一般的Web网站也不使用DELETE方法,当配合Web应用程序的验证机制,或遵守REST标准时还是有可能会开放使用的- 客户端通过
TRACE方法可以查询发送出去的请求是怎样被加工修改/篡改的,这是因为请求想要连接到源目标服务器可能会通过代理中转,TRACE方法就是用来确认连接过程中发生的一系列操作,但是TRACE方法本来就不怎么常用,再加上它容易引发XST(Cross-Site Tracing,跨站追踪)攻击,通常就更不会用到了
持久连接
HTTP 协议的初始版本中,每进行一个 HTTP 通信都要断开一次 TCP 连接,比如使用浏览器浏览一个包含多张图片的 HTML 页面时,在发送请求访问 HTML 页面资源的同时,也会请求该 HTML 页面里包含的其他资源,因此每次的请求都会造成无谓的 TCP 连接建立和断开,增加通信量的开销
为了解决上述 TCP 连接的问题,HTTP/1.1 和部分 HTTP/1.0 想出了持久连接的方法,其特点是只要任意一端没有明确提出断开连接,则保持 TCP 连接状态,旨在建立一次 TCP 连接后进行多次请求和响应的交互,在 HTTP/1.1 中,所有的连接默认都是持久连接
但是有一些需要注意的地方
HTTP Keep-Alive简单说就是保持当前的TCP连接,避免了重新建立连接HTTP长连接不可能一直保持,例如Keep-Alive: timeout=5, max=100,表示这个TCP通道可以保持5秒,max = 100,表示这个长连接最多接收100次请求就断开HTTP是一个无状态协议,这意味着每个请求都是独立的,Keep-Alive没能改变这个结果,另外Keep-Alive也不能保证客户端和服务器之间的连接一定是活跃的,在HTTP/1.1版本中也如此,唯一能保证的就是当连接被关闭时你能得到一个通知,所以不应该让程序依赖于Keep-Alive的保持连接特性,否则会有意想不到的后果- 使用长连接之后,客户端、服务端怎么知道本次传输结束呢?分为两部分
- 判断传输数据是否达到了
Content-Length指示的大小 - 动态生成的文件没有
Content-Length,它是分块传输(chunked),这时候就要根据chunked编码来判断,chunked编码的数据在最后有一个空chunked块,表明本次传输数据结束,更多详细内容可见 HTTP Keep-Alive 模式 - 关于
chunked分块传输可见下方的Transfer-Encoding部分内容
- 判断传输数据是否达到了
管线化
默认情况下 HTTP 协议中每个传输层连接只能承载一个 HTTP 请求和响应,浏览器会在收到上一个请求的响应之后,再发送下一个请求,在使用持久连接的情况下,某个连接上消息的传递类似于下面这样
1 | 请求1 -> 响应1 -> 请求2 -> 响应2 -> 请求3 -> 响应3 |
HTTP Pipelining(管线化)是将多个 HTTP 请求整批提交的技术,在传送过程中不需等待服务端的回应,使用 HTTP Pipelining 技术之后,某个连接上的消息变成了类似下面这样(注意箭头的变化)
1 | 请求1 ==> 请求2 ==> 请求3 ==> 响应1 ==> 响应2 ==> 响应3, |
这里也有一些需要注意的地方
- 管线化机制通过持久连接(
persistent connection)完成,仅HTTP/1.1支持此技术(HTTP/1.0不支持) - 只有
GET和HEAD请求可以进行管线化,而POST则有所限制 - 初次创建连接时不应启动管线机制,因为对方(服务器)不一定支持
HTTP/1.1版本的协议 - 管线化不会影响响应到来的顺序,如上面的例子所示,响应返回的顺序并未改变
HTTP/1.1要求服务器端支持管线化,但并不要求服务器端也对响应进行管线化处理,只是要求对于管线化的请求不失败即可- 由于上面提到的服务器端问题,开启管线化很可能并不会带来大幅度的性能提升,而且很多服务器端和代理程序对管线化的支持并不好,因此现代浏览器如
Chrome和Firefox默认并未开启管线化支持
HTTP 报文
用于 HTTP 协议交互的信息被称为 HTTP 报文,请求端(客户端)的 HTTP 报文叫做请求报文,响应端(服务器端)的叫做响应报文,在规范当中把 HTTP 请求分为三个部分,如下图所示
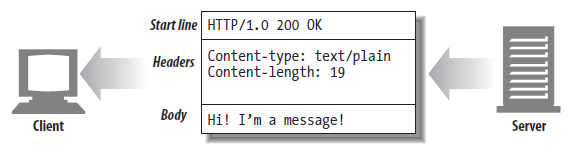
每条报文都包含一条来客户端的请求,或者一条来自客户端的响应,它们由三个部分组成,对报文进行描述的请求行(start line)、包含属性的请求头(Header)以及可选的包含数据的请求体(body),请求行与请求头就是由行分隔的 ASCII 文本,每行都以一个由两个字符组成的行终止序列作为结束,其中包括一个回车符和一个换行符,这个行终止符可以写作 CRLF(空行)
注意,尽管
HTTP规范中说明应该用CRLF来表示行终止,但稳健的做法也应该接受单个换行符作为行的终止
请求报文
HTTP 请求报文由『请求行』、『请求头』、『空行』(有时会忽略掉这一部分)和『请求体』(请求数据)四个部分组成,如下图所示
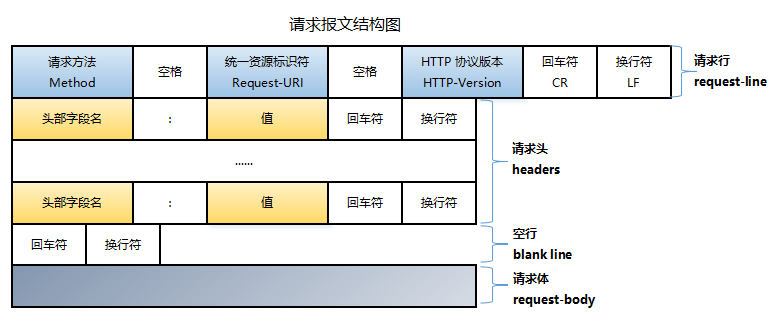
我们可以针对上图当中的内容简化一下,就变成了下面这样
1 | <method> <request-URL> <version> |
与其相对应的 HTTP 请求的报文如下
1 | GET /index.html HTTP/1.1 |
请求行
其中,下面的这行就是请求行
1 | GET /index.html HTTP/1.1 |
- 开头的
GET表示请求访问服务器的类型,称为方法,HTTP/1.1 协议 规定的HTTP请求方法有OPTIONS、GET、HEAD、POST、PUT、DELETE等,一般比较常用的是GET和POST这两个方法 - 随后的字符串
/index.htm指明了请求访问的资源对象,也叫做请求URI,如果直接与服务器进行对话,只要URL的路径部分是资源的绝对路径,通常就不会有什么问题 - 最后的
HTTP/1.1,即HTTP的版本号,用来提示客户端使用的HTTP协议功能,其格式通常是http/<major>.<minor>,其中主版本号(major)与次版本号(minor)都是整数
综合来看,大意是请求访问某台 HTTP 服务器上的 /index.htm 页面资源,在这里关于请求方法我们多看一点内容,来看两个经常会见到的问题
GET 和 POST 请求有什么区别?
我们经常看到的说法是下面这样的
GET请求参数放在URL上,POST请求参数放在请求体里GET请求参数长度有限制,POST请求参数长度可以非常大POST请求相较于GET请求安全一点点,因为GET请求的参数在URL上,且有历史记录GET请求能缓存,POST不能
但是上述答案并不完善,其实 HTTP 协议并没有要求 GET/POST 请求参数必须放在 URL 上或请求体里,也没有规定 GET 请求的长度,目前对 URL 的长度限制,是各家浏览器设置的限制,GET 和 POST 的根本区别在于 GET 请求是幂等性的,而 POST 请求不是,那么什么是幂等性呢?
幂等性,指的是对某一资源进行一次或多次请求都具有相同的副作用,例如搜索就是一个幂等的操作,而删除、新增则不是一个幂等操作
由于 GET 请求是幂等的,在网络不好的环境中,GET 请求可能会重复尝试,造成重复操作数据的风险,因此 GET 请求用于无副作用的操作(如搜索),新增/删除等操作适合用 POST,另外在网上搜索的过程中还发现有另外一个区别,那就是 GET 会产生一个 TCP 数据包,而 POST 则会产生两个 TCP 数据包,简单来说就是
- 对于
GET方式的请求,浏览器会把HTTP Header和Data一并发送出去,服务器响应200(返回数据) - 而对于
POST,浏览器先发送Header,服务器响应100 Continue,浏览器再发送Data,服务器响应200 OK(返回数据)
如果从根本上来说的话,GET 和 POST 到底是什么呢,其实就是 HTTP 协议中的两种发送请求的方法,HTTP 的底层是 TCP/IP,所以 GET 和 POST 的底层也是 TCP/IP,也就是说,GET/POST 都是 TCP 链接,而且它们能做的事情是一样一样的,你要给 GET 加上请求体,给 POST 带上 URL 参数,技术上也是完全行的通的
所以 GET 和 POST 本质上就是 TCP 链接,并无差别,但是由于 HTTP 的规定和 浏览器/服务器 的限制,导致他们在应用过程中体现出一些不同
OPTIONS 方法有什么用?
大致有以下三点
OPTIONS请求与HEAD类似,一般也是用于客户端查看服务器的性能- 这个方法会请求服务器返回该资源所支持的所有
HTTP请求方法,该方法会用'*'来代替资源名称,向服务器发送OPTIONS请求,可以测试服务器功能是否正常 JavaScript当中的XMLHttpRequest对象进行CORS跨域资源共享时,对于复杂请求,就是使用OPTIONS方法发送嗅探请求,以判断是否有对指定资源的访问权限
请求头
报文头包含若干个属性,格式为 key: value 形式的键值对,服务端据此获取客户端的信息,可以有零个或多个报文头,每个报文头都包含一个名字,后面跟着一个英文冒号(:),然后是一个可选的空格,接着是一个值,最后是一个 CRLF,报文头是由一个空行(CRLF)结束的,表示了报文头列表的结束和实体主体部分的开始,有些 HTTP 版本,比如 HTTP/1.1,要求有效的请求或响应报文中必须包含特定的报文头
关于首部字段的相关内容,会在后面的
HTTP首部字段章节当中来详细进行介绍
空行(请求)
最后一个请求头之后是一个空行,发送回车符和换行符,通知服务器以下不再有请求头
请求体
它将一个页面表单中的组件值通过键值对形式编码成一个格式化串,它承载多个请求参数的数据,报文体可以传递请求参数,请求 URL 也可以通过类似于 /index.html?param1=value1¶m2=value2 的方式传递请求参数,请求数据不在 GET 方法中使用,而是在 POST 方法中使用,与请求数据相关的最常使用的请求头是 Content-Type 和 Content-Length
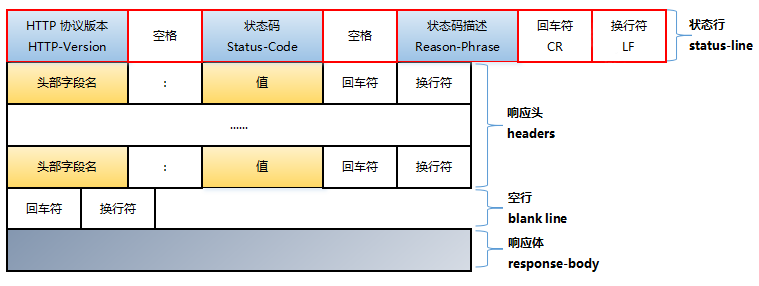
响应报文
HTTP 的响应报文由『状态行』、『响应头』、『空行』(有时会忽略掉这一部分)和『响应体』四部分组成,如下图所示
响应报文也可以进行简化,如下
1 | <version><status><reason-phrase> |
下面是一个响应报文示例
1 | HTTP/1.1 200 OK |
状态行
状态行也大致分为四个部分 HTTP-Version(HTTP 协议版本),Status-Code(状态码),Reason-Phrase(状态码描述),CRLF(回车/换行符)
其中状态码(Status-Code)的格式是三位数字,其描述了请求过程中所发生的情况,每个状态码的第一位数字用于描述状态的一般类别,一般是由以下五段组成
1xx,处理中,一般是告诉客户端,请求已经收到了,正在处理2xx,处理成功,一般表示请求已受理、已经处理完成等信息3xx,重定向到其它地方,它让客户端再发起一个请求以完成整个处理4xx,处理发生错误,错误发生在『客户端』,如客户端的请求一个不存在的资源,客户端未被授权,禁止访问等5xx,处理发生错误,错误发生在『服务端』,如服务端抛出异常,路由出错,HTTP版本不支持等
关于状态码的相关内容,会在后面的
HTTP状态码章节当中来详细进行介绍
而紧跟着后面的状态码描述(Reason-Phrase),也就是所谓的原因短语,数字状态码的可读版本,包含行终止序列之前的所有文本,原因短语只对人类有意义,比如说,尽管响应行 HTTP/1.1 200 NOT OK 和 HTTP/1.1 200 OK 中原因短语的含义不同,但同样都会被当作成功的标志,下面是一个假想的请求报文与响应报文

不过需要注意的是,一组 HTTP 报文头总是应该以一个空行(仅有 CRLF)结束,甚至即使没有报文头和实体的主体部分也应该如此,但由于历史原因,很多客户端和服务器都在没有实体的主体部分时,(错误的)省略了最后的 CRLF,为了与这些流行但不符合规则的实现兼容,客户端和服务器都应该接受那些没有最后那个 CRLF 的报文
响应头
响应头也是由格式为 key: value 形式的键值对组成,响应头域允许服务器传递不能放在状态行的附加信息,这些域主要描述服务器的信息和 Request-URI 进一步的信息
关于首部字段的相关内容,会在后面的
HTTP首部字段章节当中来详细进行介绍
空行(响应)
最后一个响应头之后是一个空行,发送回车符和换行符,通知浏览器以下不再有响应头
响应体
服务器返回给浏览器的响应信息,下面是百度首页的响应体片段
1 | <!DOCTYPE html> |
HTTP 首部字段
HTTP 协议的请求和响应报文中必定包含 HTTP 首部,只是我们平时在使用 Web 的过程中感受不到它,我们先来回顾一下首部字段在报文的位置,HTTP 报文包含报文首部和报文主体,报文首部包含请求行(或状态行)和首部字段

在报文众多的字段当中,HTTP 首部字段包含的信息最为丰富,首部字段同时存在于请求和响应报文内,并涵盖 HTTP 报文相关的内容信息,使用首部字段是为了给客服端和服务器端提供报文主体大小、所使用的语言、认证信息等内容
首部字段结构
HTTP 首部字段是由首部字段名和字段值构成的,中间用冒号 : 分隔,另外字段值对应单个 HTTP 首部字段可以有多个值,例如在 HTTP 首部中以 Content-Type 这个字段来表示报文主体的对象类型
1 | Content -Type: text/html |
另外,字段值对应单个 HTTP 首部字段可以有多个值,如下所示
1 | keep-alive: timeout=15, max-100 |
但是这里可能存在一个问题,那就是当 HTTP 报文首部中出现了两个或两个以上具有相同首部字段名时会怎么样呢?其实对于这种情况,在规范内尚未明确,根据浏览器内部处理逻辑的不同,结果可能并不一致,有些浏览器会优先处理第一次出现的首部字段,而有些则会优先处理最后出现的首部字段
首部字段类型
HTTP 首部字段根据实际用途被分为以下四种类型
| 类型 | 描述 |
|---|---|
| 通用首部字段 | 请求报文和响应报文两方都会使用的首部 |
| 请求首部字段 | 从客户端向服务器端发送请求报文时使用的首部,补充了请求的附加内容、客户端信息、响应内容相关优先级等信息 |
| 响应首部字段 | 从服务器端向客户端返回响应报文时使用的首部,补充了响应的附加内容,也会要求客户端附加额外的内容信息 |
| 实体首部字段 | 针对请求报文和响应报文的实体部分使用的首部,补充了资源内容更新时间等与实体有关的的信息 |
另外还有单独为 Cookie 服务的首部字段和一些其他的首部字段,下面我们将会一一来进行介绍
通用首部字段
通用首部字段是指,请求报文和响应报文双方都会使用的首部,它们有以下这些
| 首部字段名 | 说明 |
|---|---|
Cache-Control |
控制缓存的行为,用于随报文传送缓存指示 |
Connection |
逐挑首部、连接的管理,允许客户端和服务器指定与 请求/响应 连接有关的选项 |
Date |
提供了日期的时间标志,说明报文是什么时间创建的 |
Pragma |
报文指令,另一种随报文传送指示的方式,但并不专用缓存 |
Trailer |
报文末端的首部一览,如果报文采用了分块传输编码方式,就可以用这个首部列出位于报文拖挂部分的首部集合 |
Transfer-Encoding |
指定报文主体的传输编码方式,告知接收端为了保证报文的可靠传输,对报文采用了什么编码方式 |
Upgrade |
给出了发送端可能想要升级使用的新版本或协议 |
Via |
显示了报文经过的中间节点(代理、网关) |
Warning |
错误通知 |
Cache-Control
通过指定首部字段 Cache-Control 的指令,就能操作缓存的工作机制,指令的参数是可选的,多个指令之间通过 ,(逗号) 分隔,如下
1 | Cache-Control: private, max-age = 0, no-cache |
可用的指令按请求和响应分为两种,缓存请求指令如下所示
| 缓存请求指令 | 参数 | 说明 |
|---|---|---|
no-cache |
无 | 强制向服务器再次验证 |
no-store |
无 | 不缓存请求或响应的任何内容 |
max-age = [s] |
必需 | 响应的最大 Age 值 |
max-stale( =[s]) |
可省略 | 接收已过期的响应 |
min-fresh = [s] |
必需 | 期望在指定时间内的响应仍有效 |
no-transform |
无 | 代理不可更改媒体类型 |
only-if-cached |
无 | 从缓存获取资源 |
cache-extension |
- | 新指令标记(Token) |
缓存响应指令如下所示
| 缓存响应指令 | 参数 | 说明 |
|---|---|---|
public |
无 | 可向任意方提供响应的缓存 |
private |
可省略 | 仅向特定用户返回响应 |
no-cache |
可省略 | 缓存前必须先确认其有效性 |
no-store |
无 | 不缓存请求或响应的任何内容 |
no-transform |
无 | 代理不可更改媒体类型 |
must-revalidate |
无 | 可缓存但必须再向源服务器进行确认 |
proxy-revalidate |
无 | 要求中间缓存服务器对缓存的响应有效性再进行确认 |
max-age = [s] |
必需 | 响应的最大 Age 值 |
s-maxage = [s] |
必需 | 公共缓存服务器响应的最大 Age 值 |
cache-extension |
- | 新指令标记(Token) |
下面我们就先来看几个其中用来表示能否缓存的指令,它们有下面这几个
1 | Cache-Control: public |
当指定使用 public 指令时,则明确表明其他用户也可利用缓存
1 | Cache-Control: private |
当指定 private 指令后,响应只以特定的用户作为对象,这与 public 指令的行为相反,缓存服务器会对该特定用户提供资源缓存的服务,对于其他用户发送过来的请求,代理服务器则不会返回缓存
1 | Cache-Control: no-cache |
使用 no-cache 指令是为了防止从缓存中返回过期的资源
- 客户端发送的请求中如果包含
no-cache指令,则表示客户端将不会接收缓存过的响应,于是缓存服务器必须把客户端请求转发给源服务器 - 如果服务器中返回的响应包含
no-cache指令,那么缓存服务器不能对资源进行缓存,源服务器以后也将不再对缓存服务器请求中提出的资源有效性进行确认,且禁止其对响应资源进行缓存操作
1 | Cache-Control: no-cache = Location |
由服务器返回的响应中,若报文首部字段 Cache-Control 中对 no-cache 字段名具体指定参数值,那么客户端在接收到这个被指定参数值的首部字段对应的响应报文后,就不能使用缓存,换言之,无参数值的首部字段可以使用缓存,这里需要注意的是只能在响应指令中指定该参数
1 | Cache-Control: no-store |
当使用 no-store 指令时,暗示请求(和对应的响应)或响应中包含机密信息,因此该指令规定缓存不能在本地存储请求或响应的任一部分,这里需要注意的是,no-cache 指令代表不缓存过期的指令,缓存会向源服务器进行有效期确认后处理资源,no-store 指令才是真正的不进行缓存
看完了能否缓存的指令,我们再来看看指定缓存期限和认证的指令
1 | Cache-Control: s-maxage = 604800(单位为秒) |
s-maxage 指令的功能和 max-age 指令的相同,它们的不同点是 s-maxage 指令只适用于供多位用户使用的公共缓存服务器(一般指代理),也就是说对于向同一用户重复返回响应的服务器来说,这个指令没有任何作用
另外当使用 s-maxage 指令后,则直接忽略对 Expires 首部字段及 max-age 指令的处理
1 | Cache-Control: max-age = 604800(单位为秒) |
当客户端发送的请求中包含 max-age 指令时,如果判定缓存资源的缓存时间数值比指定的时间更小,那么客户端就接收缓存的资源,另外当指定 max-age 的值为 0,那么缓存服务器通常需要将请求转发给源服务器
当服务器返回的响应中包含 max-age 指令时,缓存服务器将不对资源的有效性再作确认,而 max-age 数值代表资源保存为缓存的最长时间,应用 HTTP/1.1 版本的缓存服务器遇到同时存在 Expires 首部字段的情况时,会优先处理 max-age 指令,并忽略掉 Expires 首部字段,而 HTTP/1.0 版本的缓存服务器则相反
1 | Cache-Control: min-fresh = 60(单位为秒) |
min-fresh 指令要求缓存服务器返回至少还未过指定时间的缓存资源,比如,当指定 min-fresh 为 60 秒后,过了 60 秒的资源都无法作为响应返回了
1 | Cache-Control: max-stale = 3600(单位为秒) |
使用 max-stale 可指示缓存资源,即使过期也照常接收,如果指令未指定参数值,那么无论经过多久,客户端都会接收响应,如果指定了具体参数值,那么即使过期,只要仍处于 max-stale 指定的时间内,仍旧会被客户端接收
1 | Cache-Control: only-if-cached |
表示客户端仅在缓存服务器本地缓存目标资源的情况下才会要求其返回,换言之,该指令要求缓存服务器不重新加载响应,也不会再次确认资源的有效性
1 | Cache-Control: must-revalidate |
使用 must-revalidate 指令,代理会向源服务器再次验证即将返回的响应缓存目前是否仍有效,另外使用 must-revalidate 指令会忽略请求的 max-stale 指令(即使已经在首部使用 max-stale)
1 | Cache-Control: proxy-revalidate |
proxy-revalidate 指令要求所有的缓存服务器在接收到客户端带有该指令的请求返回响应之前,必须再次验证缓存的有效性
1 | Cache-Control: no-transform |
使用 no-transform 指令规定无论是在请求还是响应中,缓存都不能改变实体主体的媒体类型,这样做可防止缓存或代理压缩图片等类似操作
最后我们再来看一个 Cache-Control 扩展
1 | Cache-Control: private, community = "UCI" |
通过 cache-extension 标记(Token),可以扩展 Cache-Control 首部字段内的指令,上述 community 指令即扩展的指令,如果缓存服务器不能理解这个新指令,就会直接忽略掉
Connection
Connection 首部字段具备以下两个作用
- 控制不再转发的首部字段
1 | Connection: Upgrade |
在客户端发送请求和服务器返回响应中,使用 Connection 首部字段,可控制不再转发给代理的首部字段,即删除后再转发(即 Hop-by-hop 首部)
- 管理持久连接
1 | Connection: close |
HTTP/1.1 版本的默认连接都是持久连接,当服务器端想明确断开连接时,则指定 Connection 首部字段的值为 close
1 | Connection: keep-alive |
HTTP/1.1 之前的 HTTP 版本的默认连接都是非持久连接,为此如果想在旧版本的 HTTP 协议上维持持续连接,则需要指定 Connection 首部字段的值为 keep-alive,那么我们为什么要使用 keep-alive 呢?
keep-alive 技术的创建目的,能在多次 HTTP 之前重用同一个 TCP 连接,从而减少 创建/关闭 多个 TCP 连接的开销(包括响应时间、CPU 资源、减少拥堵等),可以参考如下示意图

Date
表明创建 HTTP 报文的日期和时间
1 | Date: Mon, 10 Jul 2019 15:50:06 GMT |
HTTP/1.1 协议使用在 RFC1123 中规定的日期时间的格式
Pragma
Pragma 首部字段是 HTTP/1.1 版本之前的历史遗留字段,仅作为与 HTTP/1.0 的向后兼容而定义
1 | Pragma: no-cache |
该首部字段属于通用首部字段,但只用在客户端发送的请求中,要求所有的中间服务器不返回缓存的资源,所有的中间服务器如果都能以 HTTP/1.1 为基准,那直接采用 Cache-Control: no-cache 指定缓存的处理方式最为理想
但是要整体掌握所有中间服务器使用的 HTTP 协议版本却是不现实的,所以发送的请求会同时包含 Cache-Control: no-cache 和 Pragma: no-cache
Trailer
1 | Trailer: Expires |
首部字段 Trailer 会事先说明在报文主体后记录了哪些首部字段,可应用在 HTTP/1.1 版本分块传输编码时
Transfer-Encoding
1 | Transfer-Encoding: chunked |
规定了传输报文主体时采用的编码方式,Transfer-Encoding 是一个用来标示 HTTP 报文传输格式的头部值,尽管这个取值理论上可以有很多,但是当前的 HTTP 规范里实际上只定义了一种传输取值,chunked
如果一个 HTTP 消息(请求消息或应答消息)的 Transfer-Encoding 消息头的值为 chunked,那么消息体由数量未定的块组成,并以最后一个大小为 0 的块为结束,每一个非空的块都以该块包含数据的字节数(字节数以十六进制表示)开始,跟随一个 CRLF(回车及换行),然后是数据本身,最后块 CRLF 结束,在一些实现中,块大小和 CRLF 之间填充有白空格(0x20)
最后一块是单行,由块大小(0),一些可选的填充白空格,以及 CRLF,最后一块不再包含任何数据,但是可以发送可选的尾部,包括消息头字段,消息最后以 CRLF 结尾,一个示例响应如下
1 | HTTP/1.1 200 OK |
几个需要注意的地方
chunked和multipart两个名词在意义上有类似的地方,不过在HTTP协议当中这两个概念则不是一个类别的,multipart是一种Content-Type,标示HTTP报文内容的类型,而chunked是一种传输格式,标示报头将以何种方式进行传输chunked传输不能事先知道内容的长度,只能靠最后的空chunk块来判断,因此对于下载请求来说,是没有办法实现进度的,在浏览器和下载工具中,偶尔我们也会看到有些文件是看不到下载进度的,即采用chunked方式进行下载chunked的优势在于,服务器端可以边生成内容边发送,无需事先生成全部的内容,HTTP/2不支持Transfer-Encoding: chunked,因为HTTP/2有自己的streaming传输方式(详细可见 Transfer-Encoding)
Upgrade
1 | Upgrade: TSL/1.0 |
用于检测 HTTP 协议及其他协议是否可使用更高的版本进行通信,其参数值可以用来指定一个完全不同的通信协议
Via
1 | Via: 1.1 a1.test.com(Squid/2.7) |
为了追踪客户端和服务器端之间的请求和响应报文的传输路径,报文经过代理或网关时,会现在首部字段 Via 中附加该服务器的信息,然后再进行转发,首部字段 Via 不仅用于追踪报文的转发,还可避免请求回环的发生,所以必须在经过代理时附加该首部字段内容
Warning
该首部字段通常会告知用户一些与缓存相关的问题的警告,Warning 首部字段的格式如下,最后的日期时间可省略
1 | Warning:[警告码][警告的主机:端口号] "[警告内容]"([日期时间]) |
HTTP/1.1 中定义了七种警告,警告码对应的警告内容仅推荐参考,另外警告码具备扩展性,今后有可能追加新的警告码
| 警告码 | 警告内容 说明 |
|---|---|
110 |
Response is stale(响应已过期) 代理返回已过期的资源 |
111 |
Revalidation failed(再验证失败) 代理再验证资源有效性时失败(服务器无法到达等原因) |
112 |
Disconnection operation(断开连接操作) 代理与互联网连接被故意切断 |
113 |
Heuristic expiration(试探性过期) 响应的试用期超过 24 小时(有效缓存的设定时间大于 24 小时的情况下) |
199 |
Miscellaneous warning(杂项警告) 任意的警告内容 |
214 |
Transformation applied(使用了转换) 代理对内容编码或媒体类型等执行了某些处理时 |
299 |
Miscellaneous persistent warning(持久杂项警告) 任意的警告内容 |
请求首部字段
请求首部字段是从客户端往服务器端发送请求报文中所使用的字段,用于补充请求的附加信息、客户端信息、对响应内容相关的优先级等内容
| 请求首部字段名 | 说明 |
|---|---|
Accept |
用户代理可处理的媒体类型,也就是告诉服务器能够发送那些媒体类型 |
Accept-Charset |
优先的字符集,也就是告诉服务器能够给发送那些字符集 |
Accept-Encoding |
优先的内容编码,也就是告诉服务器能够发送那些编码方式 |
Accept-Language |
优先的语言(自然语言),也就是告诉服务器能够发送那些语言 |
Authorization |
Web 认证信息,包含了客户端提供给服务器,以便对其自身进行认证的数据 |
Expect |
期待服务器的特定行为,允许客户端列出某请求所要求的服务器行为 |
From |
用户的电子邮箱地址 |
Host |
请求资源所在服务器 |
If-Match |
比较实体标记(ETag),如果实体标记与文档当前的实体标记相匹配,就获取这份文档 |
If-Modified-Since |
比较资源的更新时间,除非在某个指定的日期之后资源被修改过,否则就限制这个请求 |
If-None-Match |
比较实体标记(与 If-Macth 相反),如果提供的实体标记与当前文档的标记不相符,就获取文档 |
If-Range |
资源未更新时发送实体 Byte 的范围请求,允许对文档的某个范围进行条件请求 |
If-Unmodified-Since |
比较资源的更新时间(与 If-Modified-Since 相反),除非在某个指定日期之后资源没有被修改过,否则就限制这个请求 |
Max-Forwards |
最大传输逐跳数,在通往源端服务器的路径上,将请求转发给其他代理或网关的最大次数,通常与 TRACE 方法一同使用 |
Proxy-Authorization |
代理服务器要求客户端的认证信息,与 Authorization 首部相同,但这个首部是在与代理进行认证时使用的 |
Range |
实体的字节范围请求,如果服务器支持范围请求,就请求资源的指定范围 |
Referer |
提供了包含当前请求 URL 的文档的 URI |
TE |
传输编码的优先级,告诉服务器可以使用那些扩展传输编码 |
User-Agent |
HTTP 客户端程序的信息,也就是将发起请求的应用程序名称告知服务器 |
Accept
1 | Accept: text/html, application/xhtml+xml, application/xml; q = 0.5 |
Accept 首部字段可通知服务器,用户代理能够处理的媒体类型及媒体类型的相对优先级,可使用 type/subtype 这种形式,一次指定多种媒体类型
若想要给显示的媒体类型增加优先级,则使用 q = [数值] 来表示权重值,用分号(;)进行分隔,权重值的范围 0 ~ 1(可精确到小数点后三位),且 1 为最大值,不指定权重值时,默认为 1,当服务器提供多种内容时,将会首先返回权重值最高的媒体类型
Accept-Charset
1 | Accept-Charset: iso-8859-5, unicode-1-1; q = 0.8 |
Accept-Charset 首部字段可用来通知服务器用户代理支持的字符集及字符集的相对优先顺序,另外可一次性指定多种字符集,同样使用 q = [数值] 来表示相对优先级
Accept-Encoding
1 | Accept-Encoding: gzip, deflate |
Accept-Encoding 首部字段用来告知服务器用户代理支持的内容编码及内容编码的优先顺序,并可一次性指定多种内容编码,同样使用 q = [数值] 来表示相对优先级,也可使用星号(*)作为通配符,指定任意的编码格式
Accept-Language
1 | Accept-Lanuage: zh-cn, zh; q = 0.7, en = us, en; q = 0.3 |
告知服务器用户代理能够处理的自然语言集(指中文或英文等),以及自然语言集的相对优先级,可一次性指定多种自然语言集,同样使用 q = [数值] 来表示相对优先级
Authorization
1 | Authorization: Basic ldfKDHKfkDdasSAEdasd== |
告知服务器用户代理的认证信息(证书值),通常想要通过服务器认证的用户代理会在接收到返回的 401 状态码响应后,把首部字段 Authorization 加入请求中,共用缓存在接收到含有 Authorization 首部字段的请求时的操作处理会略有差异
Expect
1 | Expect: 100-continue |
告知服务器客户端期望出现的某种特定行为
From
1 | From: test@email.com |
告知服务器使用用户代理的电子邮件地址
Host
1 | Host: www.test.com |
告知服务器,请求的资源所处的互联网主机和端口号,Host 首部字段是 HTTP/1.1 规范内唯一一个必须被包含在请求内的首部字段,因为请求被发送至服务器时,如果在相同的 IP 地址下部署运行着多个域名,那么服务器就会无法理解究竟是哪个域名对应的请求,因此就需要使用首部字段 Host 来明确指出请求的主机名,若服务器未设定主机名,那直接发送一个空值即可
1 | Host: |
If-Match
形如 If-xxx 这种样式的请求首部字段,都可称为条件请求,服务器接收到附带条件的请求后,只有判断指定条件为真时,才会执行请求
1 | If-Match: "123456" |
首部字段 If-Match,属附带条件之一,它会告知服务器匹配资源所用的实体标记(ETag)值,这时的服务器无法使用弱 ETag 值,服务器会比对 If-Match 的字段值和资源的 ETag 值,仅当两者一致时才会执行请求,反之则返回状态码 412 Precondition Failed 的响应
另外还可以使用星号(*)指定 If-Match 的字段值,针对这种情况服务器将会忽略 ETag 的值,只要资源存在就处理请求
If-Modified-Since
1 | If-Modified-Since: Mon, 10 Jul 2019 15:50:06 GMT |
首部字段 If-Modified-Since 属附带条件之一,用于确认代理或客户端拥有的本地资源的有效性,它会告知服务器若 If-Modified-Since 字段值早于资源的更新时间,则希望能处理该请求,而在指定 If-Modified-Since 字段值的日期时间之后,如果请求的资源都没有过更新,则返回状态码 304 Not Modified 的响应
If-None-Match
1 | If-None-Match: "123456" |
首部字段 If-None-Match 属于附带条件之一,它和首部字段 If-Match 作用相反,用于指定 If-None-Match 字段值的实体标记(ETag)值与请求资源的 ETag 不一致时,它就告知服务器处理该请求,也就是只有在 If-None-Match 的字段值与 ETag 值不一致时,才处理该请求
If-Range
1 | If-Range: "123456" |
首部字段 If-Range 属于附带条件之一,它告知服务器若指定的 If-Range 字段值(ETag 值或者时间)和请求资源的 ETag 值或时间相一致时,则作为范围请求处理,反之则返回全体资源
我们可以思考一下不使用首部字段 If-Range 发送请求的情况,服务器端的资源如果更新,那客户端持有资源中的一部分也会随之无效,当然范围请求作为前提是无效的,这时服务器会暂且以状态码 412 Precondition Failed 作为响应返回,其目的是催促客户端再次发送请求,这样一来,与使用首部字段 If-Range 比起来,就需要花费两倍的功夫
If-Unmodified-Since
1 | If-Unmodified-Since: Mon, 10 Jul 2019 15:50:06 GMT |
首部字段 If-Unmodified-Since 和首部字段 If-Modified-Since 的作用相反,它的作用的是告知服务器,指定的请求资源只有在字段值内指定的日期时间之后,未发生更新的情况下,才能处理请求,如果在指定日期时间后发生了更新,则以状态码 412 Precondition Failed 作为响应返回
Max-Forwards
1 | Max-Forwards: 10 |
通过 TRACE 方法或 OPTIONS 方法,发送包含首部字段 Max-Forwards 的请求时,该字段以十进制整数形式指定可经过的服务器最大数目,服务器在往下一个服务器转发请求之前,Max-Forwards 的值减 1 后重新赋值,当服务器接收到 Max-Forwards 值为 0 的请求时,则不再进行转发,而是直接返回响应
Proxy-Authorization
1 | Proxy-Authorization: Basic dGlwOjkpNLAGfFY5 |
接收到从代理服务器发来的认证质询时,客户端会发送包含首部字段 Proxy-Authorization 的请求,以告知服务器认证所需要的信息,这个行为是与客户端和服务器之间的 HTTP 访问认证相类似的,不同之处在于认证行为发生在客户端与代理之间
Range
1 | Range: bytes = 5001-10000 |
对于只需获取部分资源的范围请求,包含首部字段 Range 即可告知服务器资源的指定范围,接收到附带 Range 首部字段请求的服务器,会在处理请求之后返回状态码为 206 Partial Content 的响应,无法处理该范围请求时,则会返回状态码 200 OK 的响应及全部资源
Referer
1 | Referer: http://www.test.com/index.html |
首部字段 Referer 会告知服务器请求的原始资源的 URI
TE
1 | TE: gzip, deflate; q = 0.5 |
首部字段 TE 会告知服务器客户端能够处理响应的传输编码方式及相对优先级,它和首部字段 Accept-Encoding 的功能很相像,但是用于传输编码,首部字段 TE 除指定传输编码之外,还可以指定伴随 trailer 字段的分块传输编码的方式,应用后者时,只需把 trailers 赋值给该字段值
1 | TE: trailers |
User-Agent
1 | User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64; rv:13.0) Gecko/=20190101 Firefox/13.0.1 |
首部字段 User-Agent 会将创建请求的浏览器和用户代理名称等信息传达给服务器,由网络爬虫发起请求时,有可能会在字段内添加爬虫作者的电子邮件地址,此外如果请求经过代理,那么中间也很可能被添加上代理服务器的名称
响应首部字段
响应首部字段是由服务器端向客户端返回响应报文中所使用的字段,用于补充响应的附加信息、服务器信息,以及对客户端的附加要求等信息
| 响应首部字段 | 说明 |
|---|---|
Accept-Ranges |
是否接受字节范围请求,对此资源来说,服务器可接受的范围类型 |
Age |
推算资源创建经过时间,(从最初创建开始)响应持续时间 |
ETag |
资源的匹配信息 |
Location |
令客户端重定向至指定 URI |
Proxy-Authenticate |
代理服务器对客户端的认证信息 |
Retry-After |
对再次发起请求的时机要求,如果资源不可用的话,在此日期或时间重试 |
Server |
HTTP 服务器的安装信息,服务器应用程序软件的名称和版本 |
Vary |
代理服务器缓存的管理信息,也就是说,这是一个首部列表,服务器会根据这些首部的内容挑选处最合适的资源版本发送个客户端 |
WWW-Authenticate |
服务器对客户端的认证信息 |
Accept-Ranges
1 | Accept-Ranges: bytes |
首部字段 Accept-Ranges 是用来告知客户端服务器是否能处理范围请求,以指定获取服务器端某个部分的资源,可指定的字段值有两种,可处理范围请求时指定其为 bytes,反之则指定其为 none
Age
1 | Age: 600 |
首部字段 Age 能告知客户端,源服务器在多久前创建了响应,字段值的单位为秒,若创建该响应的服务器是缓存服务器,Age 值是指缓存后的响应再次发起认证到认证完成的时间值,代理创建响应时必须加上首部字段 Age
ETag
1 | ETag: "82e22293907ce725faf67773957acd12" |
首部字段 ETag 能告知客户端实体标识,它是一种可将资源以字符串形式做唯一性标识的方式,服务器会为每份资源分配对应的 ETag 值,另外当资源更新时,ETag 值也需要更新,生成 ETag 值时,并没有统一的算法规则,而仅仅是由服务器来分配
ETag 中有强 ETag 值和弱 ETag 值之分,强 ETag 值,不论实体发生多么细微的变化都会改变其值
1 | ETag: "usagi -1234" |
弱 ETag 值只用于提示资源是否相同,只有资源发生了根本改变,产生差异时才会改变 ETag 值,这时会在字段值最开始处附加 W/
1 | ETag: W/"usagi-1234" |
Location
1 | Location: http://www.test.com/index.html |
使用首部字段 Location 可以将响应接收方引导至某个与请求 URI 位置不同的资源,基本上该字段会配合 3xx: Redirection 的响应,提供重定向的 URI,几乎所有的浏览器在接收到包含首部字段 Location 的响应后,都会强制性地尝试对已提示的重定向资源的访问
Proxy-Authenticate
1 | Proxy-Authenticate: Basic realm = "Usagidesign Auth" |
首部字段 Proxy-Authenticate 会把由代理服务器所要求的认证信息发送给客户端,它与客户端和服务器之间的 HTTP 访问认证的行为相似,不同之处在于其认证行为是在客户端与代理之间进行的
Retry-After
1 | Retry-After: 120 |
首部字段 Retry-After 告知客户端应该在多久之后再次发送请求,主要配合状态码 503 Service Unavailable 响应,或 3xx Redirect 响应一起使用,字段值可以指定为具体的日期时间(Mon, 10 Jul 2019 15:50:06 GMT 等格式),也可以是创建响应后的秒数
Server
1 | Server: Apache/2.2.6 (Unix) PHP/5.2.5 |
首部字段 Server 告知客户端当前服务器上安装的 HTTP 服务器应用程序的信息,不单单会标出服务器上的软件应用名称,还有可能包括版本号和安装时启用的可选项
Vary
1 | Vary: Accept-Language |
首部字段 Vary 可对缓存进行控制,源服务器会向代理服务器传达关于本地缓存使用方法的命令,从代理服务器接收到源服务器返回包含 Vary 指定项的响应之后,若再要进行缓存,仅对请求中含有相同 Vary 指定首部字段的请求返回缓存,即使对相同资源发起请求,但由于 Vary 指定的首部字段不相同,因此必须要从源服务器重新获取资源
WWW-Authenticate
1 | WWW-Authenticate: Basic realm = "Usagidesign Auth" |
首部字段 WWW-Authenticate 用于 HTTP 访问认证,它会告知客户端适用于访问请求 URI 所指定资源的认证方案(Basic 或是 Digest)和带参数提示的质询(challenge)
实体首部字段
实体首部字段是包含在请求报文和响应报文中的实体部分所使用的首部,用于补充内容的更新时间等与实体相关的信息
| 首部字段名 | 说明 |
|---|---|
Allow |
资源可支持的 HTTP 方法 |
Content-Encoding |
实体主体适用的编码方式 |
Content-Language |
实体主体的自然语言 |
Content-Length |
实体主体的大小(单位为字节) |
Content-Location |
替代对应资源的 URI |
Content-MD5 |
实体主体的 MD5 校验和 |
Content-Range |
实体主体的位置范围,在整个资源中此实体表示的字节范围 |
Content-Type |
实体主体的媒体类型 |
Expires |
实体主体过期的日期时间,即实体不再有效,要从原始的源端再次获取此实体的日期和时间 |
Last-Modified |
资源的最后修改日期时间 |
Allow
1 | Allow: GET, HEAD |
首部字段 Allow 用于通知客户端能够支持 Request-URI 指定资源的所有 HTTP 方法,当服务器接收到不支持的 HTTP 方法时,会以状态码 405 Method Not Allowed 作为响应返回,与此同时,还会把所有能支持的 HTTP 方法写入首部字段 Allow 后返回
Content-Encoding
1 | Content-Encoding: gzip |
首部字段 Content-Encoding 会告知客户端服务器对实体的主体部分选用的内容编码方式,内容编码是指在不丢失实体信息的前提下所进行的压缩,主要采用下面这四种内容编码的方式
gzip,由文件压缩程序gzip(GNU zip)生成的编码格式(RFC1952),采用Lempel-Ziv算法(LZ77)及32位循环冗余校验(Cyclic Redundancy Check,通称CRC)compress,由UNIX文件压缩程序compress生成的编码格式,采用Lempel-Ziv-Welch算法(LZW)deflate,组合使用zlib格式(RFC1950)及由deflate压缩算法(RFC1951)生成的编码格式identity,不执行压缩或不会变化的默认编码格式
Content-Language
1 | Content-Language: zh-CN |
首部字段 Content-Language 会告知客户端,实体主体使用的自然语言(指中文或英文等语言)
Content-Length
1 | Content-Length: 15000 |
首部字段 Content-Length 表明了实体主体部分的大小(单位是字节),对实体主体进行内容编码传输时,不能再使用 Content-Length 首部字段
Content-Location
1 | Content-Location: http://www.sample.com/index.html |
首部字段 Content-Location 给出与报文主体部分相对应的 URI,和首部字段 Location 不同,Content-Location 表示的是报文主体返回资源对应的 URI
Content-MD5
1 | Content-MD5: OGFkZDUwNGVhNGY3N2MxMDIwZmQ4NTBmY2IyTY== |
首部字段 Content-MD5 是一串由 MD5 算法生成的值,其目的在于检查报文主体在传输过程中是否保持完整,以及确认传输到达
Content-Range
1 | Content-Range: bytes 5001-10000/10000 |
针对范围请求,返回响应时使用的首部字段 Content-Range,能告知客户端作为响应返回的实体的哪个部分符合范围请求,字段值以字节为单位,表示当前发送部分及整个实体大小
Content-Type
1 | Content-Type: text/html; charset=UTF-8 |
首部字段 Content-Type 说明了实体主体内对象的媒体类型,和首部字段 Accept 一样,字段值用 type/subtype 形式赋值,参数 charset 使用 iso-8859-1 等字符集进行赋值
Expires
1 | Expires: Mon, 10 Jul 2019 15:50:06 GMT |
首部字段 Expires 会将资源失效的日期告知客户端,缓存服务器在接收到含有首部字段 Expires 的响应后,会以缓存来应答请求,在 Expires 字段值指定的时间之前,响应的副本会一直被保存,当超过指定的时间后,缓存服务器在请求发送过来时,会转向源服务器请求资源
源服务器不希望缓存服务器对资源缓存时,最好在 Expires 字段内写入与首部字段 Date 相同的时间值,但是当首部字段 Cache-Control 有指定 max-age 指令时,比起首部字段 Expires,会优先处理 max-age 指令
Last-Modified
1 | Last-Modified: Mon, 10 Jul 2019 15:50:06 GMT |
首部字段 Last-Modified 指明资源最终修改的时间,一般来说这个值就是 Request-URI 指定资源被修改的时间,但类似使用 CGI 脚本进行动态数据处理时,该值有可能会变成数据最终修改时的时间
为 Cookie 服务的首部字段
管理服务器与客户端之间状态的 Cookie,虽然没有被编人标准化 HTTP/1.1 的 RFC2616 中,但在 Web 网站方面得到了广泛的应用,Cookie 的工作机制是用户识别及状态管理,Web 网站为了管理用户的状态会通过 Web 浏览器,把一些数据临时写人用户的计算机内,接着当用户访问该 Web 网站时,可通过通信方式取回之前发放的 Cookie
调用 Cookie 时,由于可校验 Cookie 的有效期,以及发送方的域、路径、协议等信息,所以正规发布的 Cookie 内的数据不会因来自其他 Web 站点和攻击者的攻击而泄露
| 首部字段名 | 说明 | 首部类型 |
|---|---|---|
Set-Cookie |
开始状态管理所使用的 Cookie 信息 |
响应首部字段 |
Cookie |
服务器接收到的 Cookie 信息 |
请求首部字段 |
Set-Cookie
1 | Set-Cookie: status=enable; expires=Mon, 10 Jul 2019 15:50:06 GMT; path=/; |
下面的表格列举了 Set-Cookie 的字段值
| 属性 | 说明 |
|---|---|
NAME=VALUE |
赋予 Cookie 的名称和其值(必需项) |
expires=DATE |
Cookie 的有效期(若不明确指定则默认为浏览器关闭前为止) |
path=PATH |
将服务器上的文件目录作为 Cookie 的适用对象(若不指定则默认为文档所在的文件目录) |
domain=域名 |
作为 Cookie 适用对象的域名 (若不指定则默认为创建 Cookie 的服务器的域名) |
Secure |
仅在 HTTPS 安全通信时才会发送 Cookie |
HttpOnly |
加以限制,使 Cookie 不能被 JavaScript 脚本访问 |
expires属性
Cookie 的 expires 属性指定浏览器可发送 Cookie 的有效期,当省略 expires 属性时,其有效期仅限于维持浏览器会话(Session)时间段内,这通常限于浏览器应用程序被关闭之前,另外,一旦 Cookie 从服务器端发送至客户端,服务器端就不存在可以显式删除 Cookie 的方法,但可通过覆盖已过期的 Cookie,实现对客户端 Cookie 的实质性删除操作
path属性
Cookie 的 path 属性可用于限制指定 Cookie 的发送范围的文件目录
domain属性
通过 Cookie 的 domain 属性指定的域名可做到与结尾匹配一致,比如当指定 example.com 后,除 example.com 以外,www.example.com 或 www2.example.com 等都可以发送 Cookie,因此除了针对具体指定的多个域名发送 Cookie 之外,不指定 domain 属性显得更安全
secure属性
1 | Set-Cookie: name=value; secure |
Cookie 的 secure 属性用于限制 Web 页面仅在 HTTPS 安全连接时,才可以发送 Cookie,当省略 secure 属性时,不论 HTTP 还是 HTTPS,都会对 Cookie 进行回收
HttpOnly属性
Cookie 的 HttpOnly 属性是 Cookie 的扩展功能,它使 JavaScript 脚本无法获得 Cookie,其主要目的为防止跨站脚本攻击(Cross-site scripting,XSS)对 Cookie 的信息窃取
1 | Set-Cookie: name=value; HttpOnly |
通过上述设置,通常从 Web 页面内还可以对 Cookie 进行读取操作,但使用 JavaScript 的 document.cookie 就无法读取附加 HttpOnly 属性后的 Cookie 的内容了,因此也就无法在 XSS 中利用 JavaScript 劫持 Cookie 了
Cookie
1 | Cookie: status = enable |
首部字段 Cookie 会告知服务器,当客户端想获得 HTTP 状态管理支持时,就会在请求中包含从服务器接收到的 Cookie,接收到多个 Cookie 时,同样可以以多个 Cookie 形式发送
其他首部字段
HTTP 首部字段是可以自行扩展的,所以在 Web 服务器和浏览器的应用上,会出现各种非标准的首部字段,下面几个是比较常见的首部字段
X-Frame-Options
1 | X-Frame-Options: DENY |
首部字段 X-Frame-Options 属于 HTTP 响应首部,用于控制网站内容在其他 Web 网站的 Frame 标签内的显示问题,其主要目的是为了防止点击劫持(clickjacking)攻击,首部字段 X-Frame-Options 有以下两个可指定的字段值
DENY,拒绝SAMEORIGIN,仅同源域名下的页面(Top-level-browsing-context)匹配时许可,(比如当指定http://test.com/index.html页面为SAMEORIGIN时,那么test.com上所有页面的frame都被允许可加载该页面,而其他域名的页面就不行了)
X-XSS-Protection
1 | X-XSS-Protection: 1 |
首部字段 X-XSS-Protection 属于 HTTP 响应首部,它是针对跨站脚本攻击(XSS)的一种对策,用于控制浏览器 XSS 防护机制的开关,首部字段 X-XSS-Protection 可指定的字段值如下
0,将XSS过滤设置成无效状态1,将XSS过滤设置成有效状态
DNT
1 | DNT: 1 |
首部字段 DNT 属于 HTTP 请求首部,其中 DNT 是 Do Not Track 的简称,意为拒绝个人信息被收集,是表示拒绝被精准广告追踪的一种方法,首部字段 DNT 可指定的字段值如下
0,同意被追踪1,拒绝被追踪
由于首部字段 DNT 的功能具备有效性,所以 Web 服务器需要对 DNT 做对应的支持
P3P
1 | P3P: CP = "CAO DSP LAW CURa ADMa DEVa TAIa PSAa PSDa IVAa IVDa OUR BUS IND" |
首部字段 P3P 属于 HTTP 响应首部,通过利用 P3P(The Platform for Privacy Preferences,在线隐私偏好平台)技术,可以让 Web 网站上的个人隐私变成一种仅供程序可理解的形式,以达到保护用户隐私的目的,要进行 P3P 的设定,需按以下操作步骤进行
- 步骤
1,创建P3P隐私 - 步骤
2,创建P3P隐私对照文件后,保存命名在/w3c/p3p.xml - 步骤
3,从P3P隐私中新建Compact policies后,输出到HTTP响应中
HTTP 报文实体
我们在之前的 HTTP 报文章节当中介绍了请求报文与响应报文相关内容,我们也了解了一些 HTTP 报文结构的相关内容,如下图
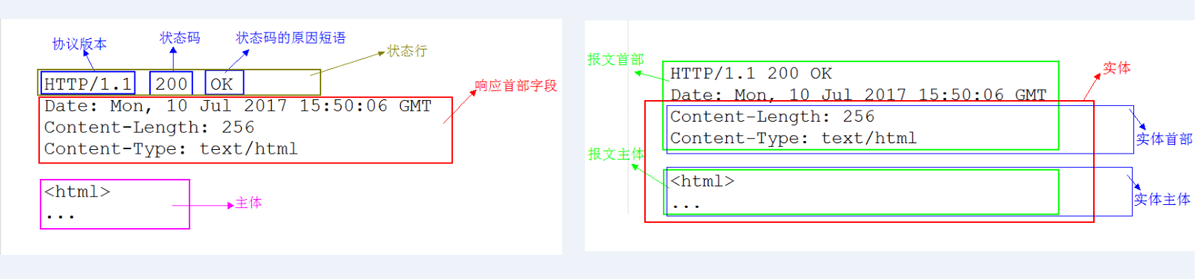
HTTP 报文实体概述
我们在上面的示例当中可以了解到各个组成部分对应的内容,这里我们主要来看报文和实体的概念,如果把 HTTP 报文想象成因特网货运系统中的箱子,那么 HTTP 实体就是报文中实际的货物
- 报文,是网络中交换和传输的数据单元,即站点一次性要发送的数据块,报文包含了将要发送的完整的数据信息,其长短很不一致,长度不限且可变
- 实体,作为请求或响应的有效载荷数据(补充项)被传输,其内容由实体首部和实体主体组成(实体首部相关内容在上面第六点中已有阐述)
我们可以看到,上面示例右图中深红色框的内容就是报文的实体部分,而蓝色框的两部分内容分别就是实体首部和实体主体,而左图中粉红框内容就是报文主体
通常,报文主体等于实体主体,只有当传输中进行编码操作时,实体主体的内容发生变化,才导致它和报文主体产生差异
内容编码
HTTP 应用程序有时在发送之前需要对内容进行编码,例如在把很大的 HTML 文档发送给通过慢速连接上来的客户端之前,服务器可能会对其进行压缩,这样有助于减少传输实体的时间,服务器还可以把内容搅乱或加密,以此来防止未授权的第三方看到文档的内容
这种类型的编码是在发送方应用到内容之上的,当内容经过内容编码后,编好码的数据就放在实体主体中,像往常一样发送给接收方,常见的内容编码类型有以下这几个
| 编码方式 | 描述 |
|---|---|
gzip |
表明实体采用 GNU zip 编码 |
compress |
表明实体采用 Unix 的文件压缩程序 |
deflate |
表明实体采用 zlib 的格式压缩的 |
identity |
表明没有对实体进行编码,当没有 Content-Encoding 首部字段时,默认采用此编码方式 |
传输编码
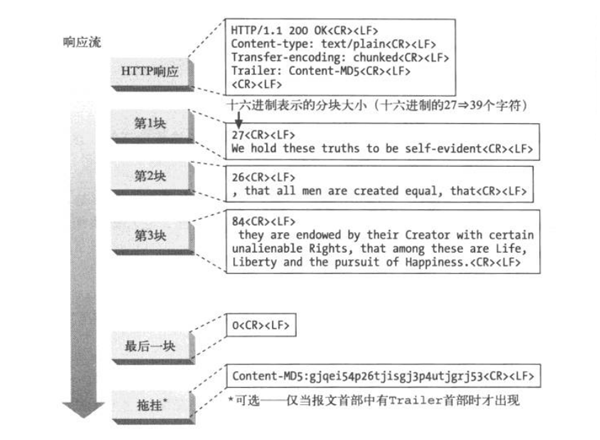
在 HTTP 通信过程中,请求的编码实体资源尚未全部传输完成之前,浏览器无法显示请求页面,在传输大容量数据时,通过把数据分割成多块,能够让浏览器逐步显示页面,这种把实体主体分块的功能称为分块传输编码(ChunkedTransfer Coding)

分块编码
分块编码把报文分割成若干已知大小的块,块之间是紧挨着发送的,这样就不需要在发送之前知道整个报文的大小了,分块编码是一种传输编码,是报文的属性
若客户端与服务器端之间不是持久连接,客户端就不需要知道它在读取的主体的长度,而只需要读取到服务器关闭主体连接为止,当使用持久连接时,在服务器写主体之前,必须知道它的大小并在 Content-Length 首部中发送,如果服务器动态创建内容,就可能在发送之前无法知道主体的长度
分块编码为这种困难提供了解决方案,只要允许服务器把主体分块发送,说明每块的大小就可以了,因为主体是动态创建的,服务器可以缓冲它的一部分,发送其大小和相应的块,然后在主体发送完之前重复这个过程,服务器可以用大小为 0 的块作为主体结束的信号,这样就可以继续保持连接,为下一个响应做准备,来看一个分块编码的报文示例
多部分媒体类型
MIME 中的 multipart(多部分)电子邮件报文中包含多个报文,它们合在一起作为单一的复杂报文发送,每一部分都是独立的,有各自的描述其内容的集,不同部分之间用分界字符串连接在一起,相应的 HTTP 协议中也采纳了多部分对象集合,发送的一份报文主体内可包含多种类型实体,多部分对象集合包含的对象如下
multipart/form-data,在Web表单文件上传时使用multipart/byteranges,状态码206 Partial Content响应报文包含了多个范围的内容时使用
在这里多提一点,就是关于 POST 请求,协议规定 POST 提交的数据必须放在消息主体(entity-body)中,但协议中并没有规定数据必须使用什么编码方式,实际上开发者完全可以自己决定消息主体的格式,只要最后发送的 HTTP 请求满足上面的格式就可以
服务端通常是根据请求头(headers)中的 Content-Type 字段来获知请求中的消息主体是用何种方式编码,再对主体进行解析,所以说到 POST 提交数据方案,包含了 Content-Type 和消息主体编码方式两部分,下面是指定为几种类型后的区别
application/x-www-form-urlencoded
这个也就是所谓的表单提交方式了,浏览器的原生 <form> 表单,如果不设置 enctype 属性,那么最终就会以 application/x-www-form-urlencoded 方式提交数据,请求类似于下面这样
1 | POST / HTTP/1.1 |
可以发现 Content-Type 被指定为 application/x-www-form-urlencoded,传递的是对应的 key 和 val
multipart/form-data
这种方式一般用来上传文件,也是一种常见的 POST 数据提交的方式,在我们使用表单上传文件时,必须让 <form> 表单的 enctype 等于 multipart/form-data
1 | POST /test.html HTTP/1.1 |
首先生成了一个 boundary 用于分割不同的字段,为了避免与正文内容重复,boundary 很长很复杂,然后 Content-Type 里指明了数据是以 multipart/form-data 来编码,指明本次请求的 boundary 是什么内容,消息主体里按照字段个数又分为多个结构类似的部分,每部分都是以 --boundary 开始,紧接着是内容描述信息,然后是回车,最后是字段具体内容(文本或二进制)
如果传输的是文件,还要包含文件名和文件类型信息,消息主体最后以 --boundary-- 标示结束,上面提到的这两种 POST 数据的方式,都是浏览器原生支持的,而且现阶段标准中原生 <form> 表单 也只支持 这两种方式,通过 <form> 元素的 enctype 属性指定,默认为 application/x-www-form-urlencoded,其实 enctype 还支持 text/plain,不过用得比较少
application/json
application/json 这个 Content-Type 一般用来告诉服务端消息主体是序列化后的 JSON 字符串,JSON 格式支持比键值对复杂得多的结构化数据,AngularJS 中的 Ajax 功能,默认就是提交 JSON 字符串
1 | var data = { 'title': 'test', 'sub': [1, 2, 3] }; |
最终发送的请求是
1 | POST http://www.example.com http/1.1 |
这种方案,可以方便的提交复杂的结构化数据,特别适合 RESTful 的接口
text/xml
这种方案现在一般使用较少,XML 作为编码方式的远程调用规范,典型的 XML-RPC 请求是这样的
1 | POST http://www.example.com http/1.1 |
XML-RPC 协议简单、功能够用,各种语言的实现都有,JavaScript 中,也有类似 XML-RPC over AJAX 这样的库来支持以这种方式进行数据交互,能很好的支持已有的 XML-RPC 服务,不过,XML 结构过于臃肿,一般场景用 JSON 会更灵活方便
范围请求
假设你正在下载一个很大的文件,已经下了四分之三,忽然网络中断了,那下载就必须重头再来一遍,为了解决这个问题,需要一种可恢复的机制,即能从之前下载中断处恢复下载,要实现该功能,这就要用到范围请求
有了范围请求,HTTP 客户端可以通过请求曾获取失败的实体的一个范围(或者说一部分),来恢复下载该实体,当然这有一个前提,那就是从客户端上一次请求该实体到这一次发出范围请求的时间段内,该对象没有改变过,例如
1 | GET /bigfile.html HTTP/1.1 |
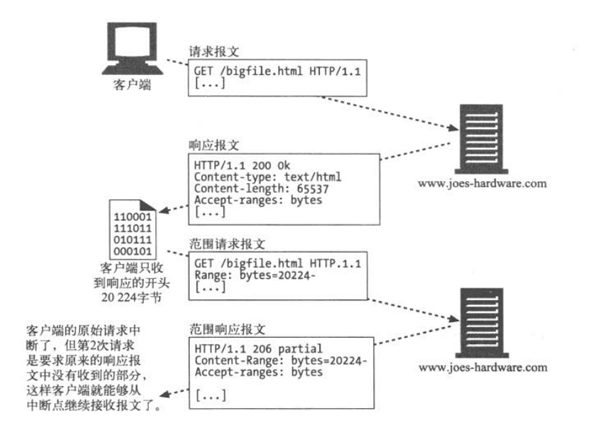
上面示例中,客户端请求的是文档开头 20224 字节之后的部分
内容协商
同一个 Web 网站有可能存在着多份相同内容的页面,比如英语版和中文版的 Web 页面,它们内容上虽相同,但使用的语言却不同,当浏览器的默认语言为英语或中文,访问相同 URI 的 Web 页面时,则会显示对应的英语版或中文版的 Web 页面,这样的机制称为内容协商(Content Negotiation)
内容协商机制是指客户端和服务器端就响应的资源内容进行交涉,然后提供给客户端最为适合的资源,内容协商会以响应资源的语言、字符集、编码方式等作为判断的基准,包含在请求报文中的某些首部字段就是判断的基准,比如以下这些
AcceptAccept-CharsetAccept-EncodingAccept-LanguageContent-Language
内容协商技术有以下三种类型,
| 类型 | 介绍 |
|---|---|
服务器驱动协商(Server-driven Negotiation) |
由服务器端进行内容协商,以请求的首部字段为参考,在服务器端自动处理,但对用户来说,以浏览器发送的信息作为判定的依据,并不一定能筛选出最优内容 |
客户端驱动协商(Agent-driven Negotiation) |
由客户端进行内容协商的方式,用户从浏览器显示的可选项列表中手动选择,还可以利用 JavaScript 脚本在 Web 页面上自动进行上述选择,比如按 OS 的类型或浏览器类型,自行切换成 PC 版页面或手机版页面 |
透明协商(Transparent Negotiation) |
是服务器驱动和客户端驱动的结合体,是由服务器端和客户端各自进行内容协商的一种方法 |
HTTP 状态码
HTTP 状态码负责表示客户端 HTTP 请求的返回结果、标记服务器端的处理是否正常、通知出现的错误等工作,状态码的职责是当客户端向服务器端发送请求时,描述返回的请求结果,借助状态码,用户可以知道服务器端是正常处理了请求,还是出现了错误,比如状态码 200 OK ,以三位数字和原因短语组成,数字中的第一位指定了响应类别,后两位无分类,响应类别有以下五种
| 状态码 | 类别 | 原因短语 |
|---|---|---|
1xx |
Informational(信息性状态码) |
代表请求已被接受,需要继续处理 |
2xx |
Success(成功状态码) |
请求正常处理完毕 |
3xx |
Redirection(重定向状态码) |
需要进行附加操作以完成请求(重定向之类) |
4xx |
Client Error(客户端错误状态码) |
服务器无法处理请求 |
5xx |
Server Error(服务器错误状态码) |
服务器处理请求出错 |
其实只要遵守状态码类别的定义,即使改变 RFC2616 中定义的状态码,或服务器端自行创建状态码都没问题,又因为 HTTP 状态码种类繁多,数量达几十种,但是比较常用的有以下这些,所以我们下面主要来看这些具有代表性质的状态码
2xx成功,该响应结果表明请求被正常处理了200 OK,表示从客户端发来的请求在服务器端被正常处理了204 No Content,代表服务器接收的请求已成功处理,但在返回的响应报文中不含实体的主体部分,另外也不允许返回任何实体的主体,一般在只需要从客户端向服务器端发送消息,而服务器端不需要向客户端发送新消息内容的情况下使用206 Partial Content,表示客户端进行了范围请求,而服务器成功执行了这部分的GET请求,响应报文中包含由Content-Range首部字段指定范围的实体内容
3xx重定向,表明浏览器需要执行某些特殊的处理以正确处理请求301 Moved Permanently,永久性重定向,可以简单地理解为该资源已经被永久改变了位置,通常会发送 HTTP Location 来 重定向 到正确的新位置302 Found,临时性重定向,表示请求的资源已被分配了新的URI,希望用户(本次)能使用新的URI访问,和301 Moved Permanently状态码相似,但302 Found状态码代表资源不是被永久移动,只是临时性质的,换句话说,已移动的资源对应的URI将来还有可能发生改变303 See Other,表示由于请求的资源存在着另一个URI,应使用GET方法定向获取请求的资源,303 See Other和302 Found状态码有着相同的功能,但303 See Other状态码明确表示客户端应采用GET方法获取资源,这点与302 Found状态码有区别(当301/302/303响应状态码返回时,几乎所有的浏览器都会把POST改成GET,并删除请求报文内的主体,之后请求会自动再次发送,本质上301/302标准是禁止将POST方法改变成GET方法的,但实际使用时大家都会这么做)304 Not Modified,未修改,自从上次请求后,请求的网页未修改过,服务器返回此响应时,不会返回网页内容,也就是说当访问资源出现304访问的情况下其实就是浏览器先在本地缓存了访问的资源,然后直接返回了缓存的资源,这里涉及到了请求头中的两个请求参数If-Modified-Since和If-None-Match,详细可见上方的HTTP首部字段章节307 Temporary Redirect,临时重定向,该状态码与302 Found有着相同的含义,尽管302标准禁止POST变换成GET,但实际使用时大家并不遵守,307会遵照浏览器标准,不会从POST变成GET,但是对于处理响应时的行为,每种浏览器有可能出现不同的情况
4xx客户端错误,表明客户端是发生错误的原因所在400 Bad Request,错误请求,服务器不理解请求的语法,常见于客户端传参错误401 Unauthorized,未授权,表示发送的请求需要有通过HTTP认证(BASIC认证、DIGEST认证)的认证信息,常见于客户端未登录403 Forbidden,禁止访问,表明对请求资源的访问被服务器拒绝了,常见于客户端权限不足,未获得文件系统的访问授权,访问权限出现某些问题(从未授权的发送源IP地址试图访问)等列举的情况都可能是发生403的原因404 Not Found,未找到,服务器找不到对应资源,除此之外,也可以在服务器端拒绝请求且不想说明理由的时候使用405 Method Not Allowed,服务器禁止使用该方法,客户端可以通过Options方法来查看服务器允许的访问方法(Access-Control-Allow-Methods)
5xx服务器错误,结果表明服务器本身发生错误500 Inter Server Error,表明服务器端在执行请求时发生了错误,无法完成请求,也可能是Web应用存在的某些临时的故障501 Not Implemented,尚未实施,服务器不具备完成请求的功能502 Bad Gateway,作为网关或者代理工作的服务器尝试执行请求时,从上游服务器接收到无效的响应503 service unavailable,服务不可用,服务器目前无法使用(处于超载或停机维护状态)通常是暂时状态
这里需要注意一点,不少返回的状态码响应都是错误的,但是用户可能察觉不到这点,比如
Web应用程序内部发生错误,状态码依然返回200 OK,这种情况也经常遇到
结构组件(代理、网关、隧道、缓存)
HTTP 通信时,除客户端和服务器以外,还有一些用于通信数据转发的应用程序,例如代理、网关和隧道等,它们可以配合服务器工作,这些应用程序和服务器可以将请求转发给通信线路上的下一站服务器,并且能接收从那台服务器发送的响应再转发给客户端
代理
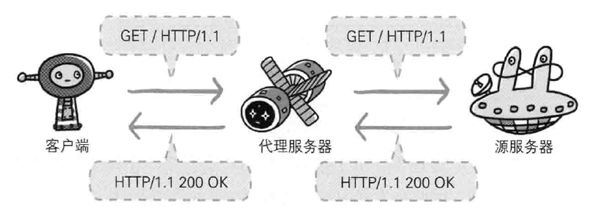
代理服务器的基本行为就是接收客户端发送的请求后转发给其他服务器,代理不改变请求 URI,会直接发送给前方持有资源的目标服务器,持有资源实体的服务器被称为源服务器,从源服务器返回的响应经过代理服务器后再传给客户端
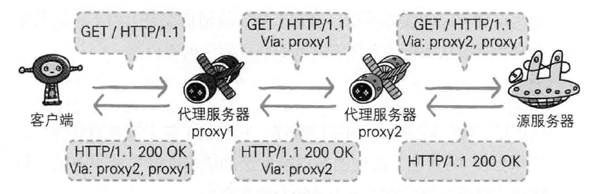
在 HTTP 通信过程中,可级联多台代理服务器,请求和响应的转发会经过数台类似锁链一样连接起来的代理服务器,转发时需要附加 Via 首部字段以标记出经过的主机信息,使用代理服务器可以利用缓存技术减少网络带宽的流量,组织内部针对特定网站的访问控制,以获取访问日志为主要目的等等
代理有多种使用方法,按两种基准分类,一种是是否使用缓存,另一种是是否会修改报文
- 缓存代理,代理转发响应时,缓存代理(
Caching Proxy)会预先将资源的副本(缓存)保存在代理服务器上,当代理再次接收到对相同资源的请求时,就可以不从源服务器那里获取资源,而是将之前缓存的资源作为响应返回 - 透明代理,转发请求或响应时,不对报文做任何加工的代理类型被称为透明代理(
Transparent Proxy),反之对报文内容进行加工的代理被称为非透明代理
网关
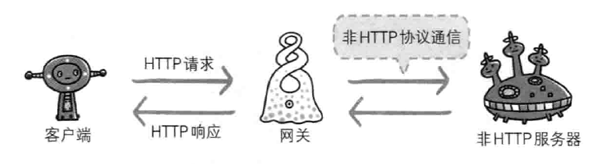
网关是一种特殊的服务器,作为其他服务器的中间实体使用,网关的工作机制和代理十分相似,而网关能使通信线路上的服务器提供非 HTTP 协议服务,利用网关能提高通信的安全性,因为可以在客户端与网关之间的通信线路上加密以确保连接的安全,比如网关可以连接数据库,使用 SQL 语句查询数据,另外在 Web 购物网站上进行信用卡结算时,网关可以和信用卡结算系统联动
隧道
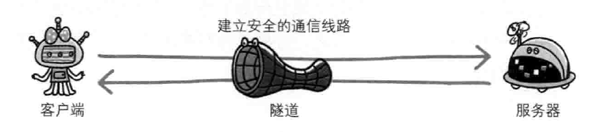
隧道可按要求建立起一条与其他服务器的通信线路,届时使用 SSL 等加密手段进行通信,隧道的目的是确保客户端能与服务器进行安全的通信,隧道本身不会去解析 HTTP 请求,也就是说,请求保持原样中转给之后的服务器,隧道会在通信双方断开连接时结束
HTTP 隧道的一种常见用途就是通过 HTTP 连接承载加密的安全套接字层(SSL)流量,这样 SSL 流量就可以穿过只允许 Web 流量通过的防火墙了
缓存
缓存是指代理服务器或客户端本地磁盘内保存的资源副本,利用缓存可减少对源服务器的访问,因此也就节省了通信流量和通信时间,缓存服务器是代理服务器的一种,并归类在缓存代理类型中,换句话说,当代理转发从服务器返回的响应时,代理服务器将会保存一份资源的副本
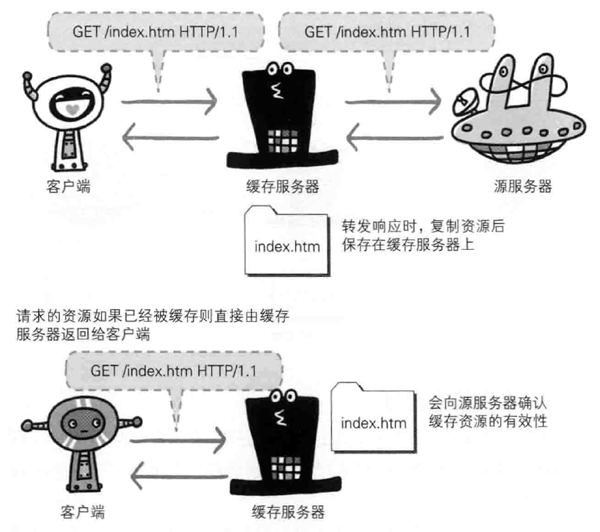
缓存服务器的优势在于利用缓存可避免多次从源服务器转发资源,因此客户端可就近从缓存服务器上获取资源,而源服务器也不必多次处理相同的请求了
缓存的有效期限
即便缓存服务器内有缓存,也不能保证每次都会返回对同资源的请求,因为这关系到被缓存资源的有效性问题,当遇上源服务器上的资源更新时,如果还是使用不变的缓存,那就会演变成返回更新前的旧资源了,即使存在缓存,也会因为客户端的要求、缓存的有效期等因素,向源服务器确认资源的有效性,若判断缓存失效,缓存服务器将会再次从源服务器上获取新资源
客户端的缓存
缓存不仅可以存在于缓存服务器内,还可以存在客户端浏览器中,浏览器缓存如果有效,就不必再向服务器请求相同的资源了,可以直接从本地磁盘内读取,另外和缓存服务器相同的一点是,当判定缓存过期后,会向源服务器确认资源的有效性,若判断浏览器缓存失效,浏览器会再次请求新资源
更多关于浏览器缓存机制的相关内容,可以参考之前整理过的 浏览器缓存机制 了解更多,其实主要依赖的还是
Cache-Control,max-age,Expires等一些头字段
HTTPS
在 HTTP 协议中有可能存在信息窃听或身份伪装等安全问题,使用 HTTPS 通信机制可以有效地防止这些问题
HTTP 的缺点
到现在为止,我们已了解到 HTTP 具有相当优秀和方便的一面,然而 HTTP 并非只有好的一面,事物皆具两面性,它也是有不足之处的,HTTP 主要有这些不足
- 通信使用明文(不加密),内容可能会被窃听
- 不验证通信方的身份,因此有可能遭遇伪装
- 无法证明报文的完整性,所以有可能已遭篡改
这些问题不仅在 HTTP 上出现,其他未加密的协议中也会存在这类问题,为了统一解决上述这些问题,需要在 HTTP 上再加入加密处理和认证等机制,我们把添加了加密及认证机制的 HTTP 称为 HTTPS(HTTP Secure)
HTTPS 并非是应用层的一种新协议,只是 HTTP 通信接口部分用 SSL(Secure Socket Layer)和 TLS(Transport Layer Security)协议代替而已,通常 HTTP 直接和 TCP 通信,当使用 SSL 时,则演变成先和 SSL 通信,再由 SSL 和 TCP 通信了,简言之所谓的 HTTPS,其实就是身披 SSL 协议这层外壳的 HTTP
HTTPS 是如何进行加密的
更多关于 HTTPS 的详细内容,我们在之前已经详细的梳理过一次,详细可见 HTTPS 是如何进行加密的,主要包括什么是 HTTPS,为什么 HTTPS 会更安全,它的整套流程又是如何实现的等相关内容
HTTP- 加密
- 多个客户端
- 对称加密秘钥如何传输
- 非对称加密
- 第三方认证
- 为什么要有签名
用户认证
我们在之前的 Cookie、Session、Token 与 JWT 章节当中简单的介绍过认证,授权和凭证相关内容,在这里我们就稍微的深入的了解一下 HTTP 当中使用的认证方式,主要有下面这些
BASIC认证(基本认证)DIGEST认证(摘要认证)SSL客户端认证FormBase认证(基于表单认证)
此外,还有 Windows 统一认证(Keberos 认证、NTLM 认证),但是在这里我们就不深入展开了,想了解更多可以自行查阅相关内容了解更多
BASIC 认证
BASIC 认证(基本认证)是从 HTTP/1.0 就定义的认证方式,即便是现在仍有一部分的网站会使用这种认证方式,是 Web 服务器与通信客户端之间进行的认证方式,步骤如下
- 步骤一,当请求的资源需要
BASIC认证时,服务器会随状态码401 Authorization Required,返回带WWW-Authenticate首部字段的响应,该字段内包含认证的方式(BASIC)及Request-URI安全域字符串(realm) - 步骤二,接收到状态码
401的客户端为了通过BASIC认证,需要将用户ID及密码发送给服务器,发送的字符串内容是由用户ID和密码构成,两者中间以冒号(:)连接后,再经过Base64编码处理 - 步骤三,接收到包含首部字段
Authorization请求的服务器,会对认证信息的正确性进行验证,如验证通过,则返回一条包含Request-URI资源的响应
BASIC 认证虽然采用 Base64 编码方式,但这不是加密处理,不需要任何附加信息即可对其解码,换言之由于明文解码后就是用户 ID 和密码,在 HTTP 等非加密通信的线路上进行 BASIC 认证的过程中,如果被人窃听,被盗的可能性极高,另外除此之外想再进行一次 BASIC 认证时,一般的浏览器却无法实现认证注销操作,这也是问题之一,BASIC 认证使用上不够便捷灵活,且达不到多数 Web 网站期望的安全性等级,因此它并不常用
DIGEST 认证
为弥补 BASIC 认证存在的弱点,从 HTTP/1.1 起就有了 DIGEST 认证,DIGEST 认证同样使用 质询/响应 的方式(challenge/response),但不会像 BASIC 认证那样直接发送明文密码
所谓质询响应方式是指,一开始一方会先发送认证要求给另一方,接着使用从另一方那接收到的质询码计算生成响应码,最后将响应码返回给对方进行认证的方式,因为发送给对方的只是响应摘要及由质询码产生的计算结果,所以比起
BASIC认证,密码泄露的可能性就降低了
DIGEST 认证的步骤如下
- 步骤一,请求需认证的资源时,服务器会随着状态码
401 Authorization Required,返回带WWW-Authenticate首部字段的响应,该字段内包含质问响应方式认证所需的临时质询码(随机
数,nonce)- 首部字段
WWW-Authenticate内必须包含realm和nonce这两个字段的信息,客户端就是依靠向服务器回送这两个值进行认证的 nonce是一种每次随返回的401响应生成的任意随机字符串,该字符串通常推荐由Base64编码的十六进制数的组成形式,但实际内容依赖服务器的具体实现
- 首部字段
- 步骤二,接收到
401状态码的客户端,返回的响应中包含DIGEST认证必须的首部字段Authorization信息,首部字段Authorization内必须包含username,realm,nonceuri和response的字段信息,其中realm和nonce就是之前从服务器接收到的响应中的字段username是realm限定范围内可进行认证的用户名uri(digest-uri)即Request-URI的值,但考虑到经代理转发后Request-URI的值可能被修改,因此事先会复制一份副本保存在uri内response也可叫做Request-Digest,存放经过MD5运算后的密码字符串,形成响应码
- 步骤三,接收到包含首部字段
Authorization请求的服务器,会确认认证信息的正确性,认证通过后则返回包含Request-URI资源的响应,并且这时会在首部字段Authentication-Info写人一些认证成功的相关信息
DIGEST 认证提供了高于 BASIC 认证的安全等级,但是和 HTTPS 的客户端认证相比仍旧很弱,DIGEST 认证提供防止密码被窃听的保护机制,但并不存在防止用户伪装的保护机制,DIGEST 认证和 BASIC 认证一样,使用上不那么便捷灵活,且仍达不到多数 Web 网站对高度安全等级的追求标准,因此它的适用范围也有所受限
SSL 客户端认证
从使用用户 ID 和密码的认证方式方面来讲,只要二者的内容正确,即可认证是本人的行为,但如果用户 ID 和密码被盗,就很有可能被第三者冒充,利用 SSL 客户端认证则可以避免该情况的发生,SSL 客户端认证是借由 HTTPS 的客户端证书完成认证的方式,凭借客户端证书认证,服务器可确认访问是否来自已登录的客户端,SSL 客户端认证的步骤如下
为达到
SSL客户端认证的目的,需要事先将客户端证书分发给客户端,且客户端必须安装此证书
- 步骤一,接收到需要认证资源的请求,服务器会发送
Certificate Request报文,要求客户端提供客户端证书 - 步骤二,用户选择将发送的客户端证书后,客户端会把客户端证书信息以
Client Crtificate报文方式发送给服务器 - 步骤三,服务器验证客户端证书验证通过后方可领取证书内客户端的公开密钥,然后开始
HTTPS加密通信
在多数情况下,SSL 客户端认证不会仅依靠证书完成认证,一般会和基于表单认证组合形成一种双因素认证来使用,所谓双因素认证就是指认证过程中不仅需要密码这一个因素,还需要申请认证者提供其他持有信息,从而作为另一个因素,与其组合使用的认证方式
换言之,第一个认证因素的 SSL 客户端证书用来认证客户端计算机,另一个认证因素的密码则用来确定这是用户本人的行为,通过双因素认证后,就可以确认是用户本人正在使用匹配正确的计算机访问服务器
基于表单认证
基于表单的认证方法并不是在 HTTP 协议中定义的,客户端会向服务器上的 Web 应用程序发送登录信息(Credential),按登录信息的验证结果认证,多数情况下,输人已事先登录的用户 ID 和密码等登录信息后,发送给 Web 应用程序,基于认证结果来决定认证是否成功
由于使用上的便利性及安全性问题,HTTP 协议标准提供的 BASIC 认证和 DIGEST 认证几乎不怎么使用,另外 SSL 客户端认证虽然具有高度的安全等级,但也存在着因为导入及维持费用等问题,不具备共同标准规范的表单认证,在每个 Web 网站上都会有各不相同的实现方式,如果是全面考虑过安全性能而实现的表单认证,那么就能够具备高度的安全等级,但在表单认证的实现中存在问题的 Web 网站也是屡见不鲜
Cookie 与 Session
这部分内容我们在 Cookie、Session、Token 与 JWT 当中已经介绍的很详细了,所以这里也就不详细展开了
追加协议
虽然 HTTP 协议既简单又简捷,但随着时代的发展,其功能使用上捉襟见肘的疲态已经凸显,本章我们就来看看基于 HTTP 新增的功能的协议
SPDY
SPDY 是 Google 开发的基于 TCP 的会话层协议,用以最小化网络延迟,提升网络速度,优化用户的网络使用体验,SPDY 并不是一种用于替代 HTTP 的协议,而是对 HTTP 协议的增强,新协议的功能包括数据流的多路复用、请求优先级以及 HTTP 报头压缩
SPDY 没有完全改写 HTTP 协议,而是在 TCP/IP 的应用层与运输层之间通过新加会话层的形式运作,同时考虑到安全性问题,SPDY 规定通信中使用 SSL,SPDY 以会话层的形式加入,控制对数据的流动,但还是采用 HTTP 建立通信连接,因此可照常使用 HTTP 的 GET 和 POST 等方法、Cookie 以及 HTTP 报文等
使用 SPDY 后,HTTP 协议额外获得以下功能
- 多路复用流,通过单一的
TCP连接,可以无限制处理多个HTTP请求,所有请求的处理都在一条TCP连接上完成,因此TCP的处理效率得到提高 - 赋予请求优先级,
SPDY不仅可以无限制地并发处理请求,还可以给请求逐个分配优先级顺序,这样主要是为了在发送多个请求时,解决因带宽低而导致响应变慢的问题 - 压缩
HTTP首部,压缩HTTP请求和响应的首部,这样一来通信产生的数据包数量和发送的字节数就更少了 - 推送功能,支持服务器主动向客户端推送数据的功能,这样服务器可直接发送数据,而不必等待客户端的请求
- 服务器提示功能,服务器可以主动提示客户端请求所需的资源,由于在客户端发现资源之前就可以获知资源的存在,因此在资源已缓存等情况下,可以避免发送不必要的请求
SPDY 的确是一种可有效消除 HTTP 瓶颈的技术,但很多 Web 网站存在的问题并非仅仅是由 HTTP 瓶颈所导致,对 Web 本身的速度提升,还应该从其他可细致钻研的地方人手,比如改善 Web 内容的编写方式等
WebSocket
WebSocket,即 Web 浏览器与 Web 服务器之间全双工通信标准,其中 WebSocket 协议由 IETF 定为标准,WebSocket API 由 W3C 定为标准,WebSocket 技术主要是为了解决 Ajax 和 Comet 里 XMLHttpRequest 附带的缺陷所引起的问题
一且 Web 服务器与客户端之间建立起 WebSocket协议的通信连接,之后所有的通信都依靠这个专用协议进行,通信过程中可互相发送 JSON、XML、HTML 或图片等任意格式的数据,由于是建立在 HTTP 基础上的协议,因此连接的发起方仍是客户端,而一旦确立 WebSocket 通信连接,不论服务器还是客户端,任意一方都可直接向对方发送报文
WebSocket协议的主要特点有以下这些
- 推送功能,支持由服务器向客户端推送数据的推送功能,这样服务器可直接发送数据,而不必等待客户端的请求
- 减少通信量,只要建立起
WebSocket连接,就希望一直保持连接状态,和HTTP相比,不但每次连接时的总开销减少,而且由于WebSocket的首部信息很小,通信量也相应减少了
一个实际的使用方式可以参考 在 Angular 当中使用 WebSocket
WebDAV
WebDAV(Web-based Distributed Authoring and Versioning)是一种基于 HTTP/1.1 协议的通信协议,它扩展了 HTTP/1.1,在 GET、POST、HEAD 等几个 HTTP 标准方法以外添加了一些新的方法,使应用程序可对 Web Server 直接读写,并支持写文件锁定(Locking)及解锁(Unlock),还可以支持文件的版本控制
针对服务器上的资源,WebDAV 新增加了一些概念
- 集合(
Collection)是一种统一管理多个资源的概念,以集合为单位可进行各种操作,也可实现类似集合的集合这样的叠加 - 资源(
Resource)把文件或集合称为资源 - 属性(
Property)定义资源的属性,定义以键值对的格式执行 - 锁(
Lock)把文件设置成无法编辑状态,多人同时编辑时,可防止在同一时间进行内容写入
WebDAV 为实现远程文件管理,向 HTTP/1.1 中追加了以下这些方法
PROPFIND,获取属性PROPPATCH,修改属性MKCOL,创建集合COPY,复制资源及属性MOVE,移动资源LOCK,资源加锁UNLOCK,资源解锁
为配合扩展的方法,状态码也随之扩展
102 Processing,可正常处理请求,但目前是处理中状态207 Multi-Status,存在多种状态422 Unprocessible Entit,格式正确,内容有误423 Locked,资源已被加锁424 Failed Dependency,处理与某请求关联的请求失败,因此不再维持依赖关系507 Insufficient Storage,保存空间不足
HTTP/2
因为内容较多,所以另外单开一章进行梳理,详细可见 HTTP/2,内容包括
HTTP/2的前身HTTP应用场景- 带宽和延迟
- 解决队头阻塞
- 开拓者
SPDY HTTP/2- 连接
- 帧
- 帧大小/帧格式/帧定义
- 流
- 流的生命周期
- 流的状态
- 流的标识符
- 连接、流和帧的关系
- 消息/流量控制/请求优先级
HTTP/2主要改动- 多路复用
- 首部压缩(
Header Compression) - 服务端推送(
Server Push)
HTTP/3
同 HTTP/2 类似,内容也较多,所以另外单开一章进行梳理,详细可见 HTTP/3,内容包括
RTTHTTP/1.xHTTP/2HTTP/3QUIC协议- 零
RTT建立连接 - 连接迁移
- 队头阻塞/多路复用
- 拥塞控制
- 流量控制
安全
简单的 HTTP 协议本身并不存在安全性问题,因此协议本身几乎不会成为攻击的对象,应用 HTTP 协议的服务器和客户端,以及运行在服务器上的 Web 应用等资源才是攻击目标,对 Web 应用的攻击模式有以下两种
- 以服务器为目标的主动攻击(
active attack)是指攻击者通过直接访问Web应用,把攻击代码传人的攻击模式,由于该模式是直接针对服务器上的资源进行攻击,因此攻击者需要能够访问到那些资源,主动攻击模式里具有代表性的攻击是SQL注人攻击和OS命令注人攻击 - 以服务器为目标的被动攻击(
passive atack)是指利用圈套策略执行攻击代码的攻击模式,在被动攻击过程中,攻击者不直接对目标Web应用访问发起攻击,被动攻击通常的攻击模式如下所示- 步骤一,攻击者诱使用户触发已设置好的陷阱,而陷阱会启动发送已嵌人攻击代码的
HTTP请求 - 步骤二,当用户不知不觉中招之后,用户的浏览器或邮件客户端就会触发这个陷阱
- 步骤三,中招后的用户浏览器会把含有攻击代码的
HTTP请求发送给作为攻击目标的Web应用,运行攻击代码 - 步骤四,执行完攻击代码,存在安全漏洞的
Web应用会成为攻击者的跳板,可能导致用户所持的Cookie等个人信息被窃取,登录状态中的用户权限遭恶意滥用等后果,被动攻击模式中具有代表性的攻击是跨站脚本攻击和跨站点请求伪造
- 步骤一,攻击者诱使用户触发已设置好的陷阱,而陷阱会启动发送已嵌人攻击代码的
因输出值转义不完全引发的安全漏洞
实施 Web 应用的安全对策可大致分为以下两部分
- 客户端的验证
Web应用端(服务器端)的验证- 输入值验证
- 输出值转义
跨站脚本攻击
跨站脚本攻击(Cross-Site Scripting,XSS)是指通过存在安全漏洞的 Web 网站注册用户的浏览器内运行非法的 HTML 标签或 JavaScript 进行的一种攻击,动态创建的 HTML 部分有可能隐藏着安全漏洞,就这样,攻击者编写脚本设下陷阱,用户在自己的浏览器上运行时,一不小心就会受到被动攻击,跨站脚本攻击有可能造成以下影响
- 利用虚假输入表单骗取用户个人信息
- 利用脚本窃取用户的
Cookie值,被害者在不知情的情况下,帮助攻击者发送恶意请求 - 显示伪造的文章或图片
SQL 注入攻击
SQL 注人(SQL Injection)是指针对 Web 应用使用的数据库,通过运行非法的 SQL 而产生的攻击,该安全隐患有可能引发极大的威胁,有时会直接导致个人信息及机密信息的泄露
Web 应用通常都会用到数据库,当需要对数据库表内的数据进行检索或添加、删除等操作时,会使用 SQL 语句连接数据库进行特定的操作,如果在调用 SQL 语句的方式上存在疏漏,就有可能执行被恶意注人(Injection)非法 SQL 语句,SQL 注人攻击有可能会造成以下等影响
- 非法查看或篡改数据库内的数据
- 规避认证
- 执行和数据库服务器业务关联的程序等
OS 命令注入攻击
OS 命令注人攻击(OS CommandInjection)是指通过 Web 应用,执行非法的操作系统命令达到攻击的目的,只要在能调用 Shell 函数的地方就有存在被攻击的风险,可以从 Web 应用中通过 Shell 来调用操作系统命令,倘若调用 Shell 时存在疏漏,就可以执行插人的非法 OS 命令
OS 命令注人攻击可以向 Shell 发送命令,让 Windows 或 Linux 操作系统的命令行启动程序,也就是说,通过 OS 注人攻击可执行 OS 上安装着的各种程序
HTTP 首部注入攻击
HTTP 首部注人攻击(HTTP Header Injection)是指攻击者通过在响应首部字段内插入换行,添加任意响应首部或主体的一种攻击,属于被动攻击模式,向首部主体内添加内容的攻击称为 HTTP 响应截断攻击(HTTP Response Sliting Attack),如下所示,Web 应用有时会把从外部接收到的数值,赋给响应首部字段 Location 和 Set-Cookie(这里的 12345 就是插入值)
1 | Location: http://www.example.com/a.cgi?q=12345 |
HTTP 首部注人可能像这样,通过在某些响应首部字段需要处理输出值的地方,插入换行发动攻击,HTTP 首部注人攻击有可能会造成以下一些影响
- 设置任何
Cookie信息 - 重定向至任意
URL - 显示任意的主体(
HTTP响应截断攻击)
HTTP 响应截断攻击
HTTP 响应截断攻击是用在 HTTP 首部注人的一种攻击,攻击顺序相同,但是要将两个 %0D%0A%0D%0A 并排插入字符串后发送,利用这两个连续的换行就可作出 HTTP 首部与主体分隔所需的空行了,这样就能显示伪造的主体,达到攻击目的,这样的攻击叫做 HTTP 响应截断攻击,如下
1 | %0D%0A%0D%0A<HTML><HEAD><TITLE>之后,想要显示的网页内容<!-- |
在可能进行 HTTP 首部注人的环节,通过发送上面的字符串,返回结果得到以下这种响应
1 | Set-Cookie: UID = (%0D%0A: 换行符) |
利用这个攻击,已触发陷阱的用户浏览器会显示伪造的 Web 页面,再让用户输入自己的个人信息等,可达到和跨站脚本攻击相同的效果
另外,滥用 HTTP/1.1 中汇集多响应返回功能,会导致缓存服务器对任意内容进行缓存操作,这种攻击称为缓存污染,使用该缓存服务器的用户,在浏览遭受攻击的网站时,会不断地浏览被替换掉的 Web 网页
邮件首部注入攻击
邮件首部注人(Mail Header Injection)是指 Web 应用中的邮件发送功能,攻击者通过向邮件首部 To 或 Subject 内任意添加非法内容发起的攻击,利用存在安全漏洞的 Web 网站,可对任意邮件地址发送广告邮件或病毒邮件
目录遍历攻击
目录遍历(Directory Traversal)攻击是指对本无意公开的文件目录,通过非法截断其目录路径后,达成访问目的的一种攻击,这种攻击有时也称为路径遍历(Path Traversal)攻击
通过 Web 应用对文件处理操作时,在由外部指定文件名的处理存在疏漏的情况下,用户可使用 ../ 等相对路径定位到 /etc/passed 等绝对路径上,因此服务器上任意的文件或文件目录皆有可能被访问到,这样一来,就有可能非法浏览、篡改或删除 Web 服务器上的文件,固然存在输出值转义的问题,但更应该关闭指定对任意文件名的访问权限
远程文件包含漏洞
远程文件包含漏洞(Remote File Inclusion)是指当部分脚本内容需要从其他文件读人时,攻击者利用指定外部服务器的 URL 充当依赖文件,让脚本读取之后,就可运行任意脚本的一种攻击
这主要是 PHP 存在的安全漏洞,对 PHP 的 include 或 require 来说,这是一种可通过设定,指定外部服务器的 URL 作为文件名的功能,但是该功能太危险,PHP 5.2.0 之后默认设定此功能无效,固然存在输出值转义的问题,但更应控制对任意文件名的指定
因设置或设计上的缺陷引发的安全漏洞
因设置或设计上的缺陷引发的安全漏洞是指错误设置 Web 服务器,或是由设计上的一些问题引起的安全漏洞
强制浏览
强制浏览(Forced Browsing)安全漏洞是指,从安置在 Web 服务器的公开目录下的文件中,浏览那些原本非自愿公开的文件,强制浏览有可能会造成以下一些影响
- 泄露顾客的个人信息等重要情报
- 泄露原本需要具有访问权限的用户才可查阅的信息内容
- 泄露未外连到外界的文件
对那些原本不愿公开的文件,为了保证安全会隐蔽其 URL,可一旦知道了那些 URL,也就意味着可浏览 URL 对应的文件,直接显示容易推测的文件名或文件目录索引时,通过某些方法可能会使 URL 产生泄露
不正确的错误消息处理
不正确的错误消息处理(Eror Handling Vulnerability)的安全漏洞是指 Web 应用的错误信息内包含对攻击者有用的信息,与 Web 应用有关的主要错误信息如下所示
Web应用抛出的错误消息- 数据库等系统抛出的错误消息
Web 应用不必在用户的浏览画面上展现详细的错误消息,对攻击者来说,详细的错误消息有可能给他们下一次攻击以提示
开放重定向
开放重定向(OpenRedirect)是一种对指定的任意 URL 作重定向跳转的功能,而于此功能相关联的安全漏洞是指,假如指定的重定向 URL 到某个具有恶意的 Web 网站,那么用户就会被诱导至那个 Web 网站
因会话管理疏忽引发的安全漏洞
会话管理是用来管理用户状态的必备功能,但是如果在会话管理上有所疏忽,就会导致用户的认证状态被窃取等后果
会话劫持
会话劫持(Session Hijack)是指攻击者通过某种手段拿到了用户的会话 ID,并非法使用此会话 ID 伪装成用户,达到攻击的目的,具备认证功能的 Web 应用,使用会话 ID 的会话管理机制,作为管理认证状态的主流方式,会话 ID 中记录客户端的 Cookie 等信息,服务器端将会话 ID 与认证状态进行一对一匹配管理,下面列举了几种攻击者可获得会话 ID 的途径
- 通过非正规的生成方法推测会话
ID - 通过窃听或
XSS攻击盗取会话ID - 通过会话固定攻击(
Session Fixation)强行获取会话ID
会话固定攻击
对以窃取目标会话 ID 为主动攻击手段的会话劫持而言,会话固定攻击(Session Fixation)攻击会强制用户使用攻击者指定的会话 ID,属于被动攻击
跨站点请求伪造
跨站点请求伪造(Cross-Site Request Forgeries,CSRF)攻击是指攻击者通过设置好的陷阱,强制对已完成认证的用户进行非预期的个人信息或设定信息等某些状态更新,属于被动攻击,跨站点请求伪造有可能会造成以下等影响
- 利用已通过认证的用户权限更新设定信息等
- 利用已通过认证的用户权限购买商品
- 利用已通过认证的用户权限在留言板上发表言论
其他安全漏洞
下面我们再来看一些不太常见的方式
密码破解
密码破解攻击(Password Cracking)即算出密码,突破认证,攻击不仅限于 Web 应用,还包括其他的系统(如 FTP 或 SSH 等),密码破解有以下两种手段
通过网络的密码试错
对 Web 应用提供的认证功能,通过网络尝试候选密码进行的一种攻击,主要有以下两种方式
- 穷举法(
Brute-force Attack,又称暴力破解法)是指对所有密钥集合构成的密钥空间(Keyspace)进行穷举,即用所有可行的候选密码对目标的密码系统试错,用以突破验证的一种攻击 - 字典攻击是指利用事先收集好的候选密码(经过各种组合方式后存人字典),枚举字典中的密码,尝试通过认证的一种攻击手法
对已加密密码的破解(指攻击者入侵系统,已获得加密或散列处理的密码数据的情况)
Web 应用在保存密码时,一般不会直接以明文的方式保存,通过散列函数做散列处理或加 salt 的手段对要保存的密码本身加密,那即使攻击者使用某些手段窃取密码数据,如果想要真正使用这些密码,则必须先通过解码等手段,把加密处理的密码还原成明文形式,从加密过的数据中导出明文通常有以下几种方法
- 通过穷举法(字典攻击进行类推),针对密码使用散列函数进行加密处理的情况,采用和穷举法或字典攻击相同的手法,尝试调用相同的散列函数加密候选密码,然后把计算出的散列值与目标散列值匹配,类推出密码
- 彩虹表(
Rainbow Table)是由明文密码及与之对应的散列值构成的一张数据库表,是一种通过事先制作庞大的彩虹表,可在穷举法等实际破解过程中缩短消耗时间的技巧,从彩虹表内搜索散列值就可以推导出对应的明文密码 - 拿到密钥,使用共享密钥加密方式对密码数据进行加密处理的情况下,如果能通过某种手段拿到加密使用的密钥,也就可以对密码数据解密了
- 加密算法的漏洞考虑到加密算法本身可能存在的漏洞,利用该漏洞尝试解密也是一种可行的方法,而
Web应用开发者独立实现的加密算法,想必尚未经过充分的验证,还是很有可能存在漏洞的
点击劫持
点击劫持(Clickjacking)是指利用透明的按钮或链接做成陷阱,覆盖在 Web 页面之上,然后诱使用户在不知情的情况下,点击那个链接访问内容的一种攻击手段,这种行为又称为界面伪装(UI Redressing)
已设置陷阱的 Web 页面,表面上内容并无不妥,但早已埋入想让用户点击的链接,当用户点击到透明的按钮时,实际上是点击了已指定透明属性元素的 ifame 页面
DoS 攻击
DoS 攻击(Denial of Service attack)是一种让运行中的服务呈停止状态的攻击,有时也叫做服务停止攻击或拒绝服务攻击,DoS 攻击的对象不仅限于 Web 网站,还包括网络设备及服务器等,
主要有以下两种 DoS 攻击方式
- 集中利用访问请求造成资源过载,资源用尽的同时,实际上服务也就呈停止状态
- 通过攻击安全漏洞使服务停止
其中,集中利用访问请求的 DoS 攻击,单纯来讲就是发送大量的合法请求,服务器很难分辨何为正常请求,何为攻击请求,因此很难防止 DoS 攻击
多台计算机发起的 DoS 攻击称为 DDoS 攻击(Distributed Denial of Service attack),DDoS 攻击通常利用那些感染病毒的计算机作为攻击者的攻击跳板
后门程序
后门程序(Backdoor)是指开发设置的隐藏入口,可不按正常步骤使用受限功能,利用后门程序就能够使用原本受限制的功能,通常的后门程序分为以下三种类型
- 开发阶段作为
Debug调用的后门程序 - 开发者为了自身利益植入的后门程序
- 攻击者通过某种方法设置的后门程序
可通过监视进程和通信的状态发现被植人的后门程序,但设定在 Web 应用中的后门程序,由于和正常使用时区别不大,通常很难发现


